俗话说得好,万事开头难。在软件开发中,环境部署要算是第一门槛了。我最近折腾了一周时间把cdh5.0.2.tar.gz版本在MRv1模式下,成功集成了Kerberos安全认证,并且是在全分布式模式下。经过这次安装过程,对hadoop的了解又深入了一层。现在趁着自己刚搭建完环境,脑子还时不时的闪现遇到的错误,把我的安装过程记录于此,一方面方便自己今后查阅,另一方面希望对今后遇到同样问题人有所启发。
首先说下为什么要用tarball安装,cdh提供了一种manager方式进行安装,对Debian系列提供apt-get,对Redhat系列提供yum安装,但是这些安装方式把一些细节都替我们做了,如果我们今后希望遇到出现什么情况,不方便调试。另外,作为一个爱折腾的人,tar.gz也是我按照软件的首选。
先说下我的搭建环境,4台Centos6.5服务器,一台做master,运行namenode、jobtracker;另外三台运行datanode、tasktracker。此外master机器上还运行Kerberos服务器。JDK的版本是1.7.60。关于5.0.2版本的环境要求可以参考http://www.cloudera.com/content/support/en/downloads/cdh/cdh-5-0-2.html#SystemRequirements。
这篇文章主要是我在参照cloudera官网的教程时遇到的坑。大家可以先去看看这个教程,再来看我的文章。
cdh5.0.2这里不再使用hadoop用户,取而代之的是mapred用户与hdfs用户,这里需要分别为它们生产ssh的公钥与秘钥,并且配置免密码登录(当然你可以为其中一个生产,然后直接copy过去)。
1. Kerberos安装
首先,Kerberos的原理、安装什么大家自己去维基百科去查,具体命令像kinit、kadmin怎么用也是大家自己查,以后有时间我会单独抽时间讲讲Kerberos。 大家现在可以按照这个文章来进行操作:Kerberos deploy guide。
后面需要为集群中每个节点的mapred与hdfs用户生成各自的principal与keytab,所以这里大家一定要熟悉kerberos的命令,把这些东西做成脚本,要不能烦死你。
2. CDH5.0.2.tar.gz安装
2.1 下载相关tar包
首先在这里http://archive.cloudera.com/cdh5/cdh/5/下载5.0.2的hadoop的tar包hadoop-2.3.0-cdh5.0.2.tar.gz,除了这个外,为了集成Kerberos,还需要下载bigtop-jsvc-1.0.10-cdh5.0.2.tar.gz。
2.2 YARN模式改成MRv1模式
这里需要讲一点是,5.0.2 tarball版本模式是YARN模式,我这里搭建的是MRv1(也就是普通的MapReduce)模式,所以需要对tar包解压出的文件做一些修改。
把hadoop-2.3.0-cdh5.0.2.tar.gz解压,假设你解压到了/opt目录下,把hadoop-2.3.0-cdh5.0.2直接重命名为hadoop(现在你的cdh根目录是/opt/hadoop),下面进行我们的修改工作:
- 把bin-mapreduce1的所以文件拷贝到bin下,对于相同的文件,直接覆盖即可。
- 在/opt/hadoop/share/hadoop文件夹下有如下的文件结构
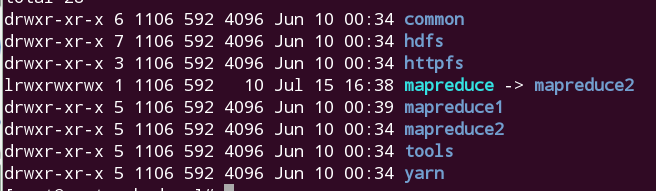
把其中的mapreduce这个软链接文件删除,然后创建一个同名的软链接指向mapreduce1
cd /opt/hadoop/share/hadoop/
rm mapreduce -rf
ln -s mapreduce1 mapreduce
经过上面这两步后,就默认启用了MRv1模式了,大家可以先把不带Kerberos安全认证的全分布式搭建起来,等到不带Kerberos安全认证的全分布式搭建起来后(可参考Hadoop全分布式搭建),再进行下面的操作。
2.3 配置HDFS
下面大家就可以按照官网的教程进行操作,下面说下我遇到的坑:
- 在STEP 2中,必须参照MRv1 cluster deploy,在hdfs中创建/tmp,与mapred.system.dir制定的目录,并且修改为相应的权限。
- 在STEP 7中,最后的dfs.http.policy这个property不用配置,否则在后面启动namnode是会报.keystore文件找不到的异常。
- STEP 8、9、10可选,配不配都行
- 在STEP 11中,需要配置JSVC_HOME这个属性,这里把我们一开始下载的bigtop-jsvc-1.0.10-cdh5.0.2.tar.gz解压后,放到它制定的位置上即可。
- 在STEP 12、13,启动datanode、namenode时,用sbin下的命令
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemons.sh start datanode
这两条命令都是用root用户执行。
在这过程中,如果遇到什么logs文件夹不能写入,将其权限改为777即可。
2.4 配置mapreduce
配置mapreduce接着参考官方的教程,下面继续说我遇到的坑:
- 首先是taskcontroller.cfg文件问题,hadoop会在
/../../conf/下去找这个文件,所以我们需要在/opt/hadoop下面(也就是我们解压后的根目录下),创建一个conf文件,然后在按照官方说的配置就行了,官方教程中有一条
banned.users=mapred,hdfs,bin
这里这样配置后,后面运行wordcount会报异常,这里可直接将其值配置为bin即可
- 然后就是task-controller这个文件的权限问题了,一定要用下面命令进行修改
chown root:mapred task-controller
chmod 4754 task-controller
其解释也在官网上有。
- 当这一切都配置好后,启动jobtracker与tasktracker还是有错,这个错误是
2014-07-15 18:15:25,722 ERROR org.apache.hadoop.mapred.TaskTracker: Can not start task tracker because java.io.IOException: Secure IO is necessary to run a secure task tracker.
at org.apache.hadoop.mapred.TaskTracker.checkSecurityRequirements(TaskTracker.java:943)
at org.apache.hadoop.mapred.TaskTracker.initialize(TaskTracker.java:976)
at org.apache.hadoop.mapred.TaskTracker.<init>(TaskTracker.java:1780)
at org.apache.hadoop.mapred.TaskTracker.main(TaskTracker.java:4124)
这个错误是因为缺少native包所致,这个包应该是在/opt/hadoop/lib/native/,很遗憾,这些东西需要我们自己编译,因为每个版本都不一样,我把apache hadoop的native直接copy过去也不行。这里我偷了个懒,直接从同事那里copy过来了。以后会说说如何从源码编译。下面说说如何编译。
cdh的源码都放在src文件夹下,安装好maven后直接到这个文件夹下编译就可以,我这里使用的是centos6.5编译的,遇到的问题主要有:
1. maven repository经常连接不上,需要多次重复操作。以后最好做一个本地repo
2. centos上需要自己安装一些依赖,否则回报各种错误,可以用下面这条命令
yum install -y glibc-headers gcc-c++ zlib-devel openssl-devel
3. 一些test通过不了,需要跳过,用下面这条命令进行编译
mvn package -Pdist,native -DskipTests
好了,如果在编译过程中还是遇到什么依赖缺失,直接去google下就ok了。
- 在用root启动jobtracker与tasktracker命令行会有错误信息,提示我们不能直接用root启动这两个进程,在haooop-env.sh配置下面的信息就好了
export HADOOP_JOBTRACKER_USER=mapred
export HADOOP_TASKTRACKER_USER=mapred
启动的命令是
sbin/hadoop-daemon.sh start jobtracker
sbin/hadoop-daemons.sh start tasktracker
也有由root启动。
3. 总结
这次搭建过程前前后后用了一个星期,麻烦是一回事,各种权限问题,最主要是还是我对hadoop的基本组成不够了解,hadoop的各个部分都是分开的,在share/hadoop目录下的每个文件夹都对应与一个功能,我一开始就想着把他们都放一起,导致不同模块的配置文件重复并产生冲突,最后导致进程起不来,今后还是要加强对基本概念的理解。其次是遇到错误多看看日志文件,很多错误能够直接根据错误信息就能够改正。
还有需要吐槽的就是不能完全按部就班的照着教程来操作,应该先看看像faq这些信息,做到有个整体上的把握,不至于拆了东墙补西墙,到最后也没能完全解决问题。
下面进行HA的环境搭建,这次一定要提高效率了!!!