记得在上大学那会,就想着能够实现个自己的编程语言。由于之前技能不足,一直没敢去尝试。现赶上国庆七天假期,SICP 看的也正起劲,终于鼓起勇气,把这个坑给填上了。甚是开心。
实现 JCScheme 这个语言前后大概用了一天时间,功能虽然简单,但是“麻雀虽小,五脏俱全”,编程语言中最基本的类型、作用域、函数都涵盖了,以后在扩展时也很方便。
如果你和之前的我一样,想实现一门语言但又苦于无从下手,那么你应该花半个小时看看本文,相信你肯定会有所收获。
本文没有复杂难懂的编译原理知识,没有学过编译原理的人不要害怕。
JCScheme 完整代码托管到我的 Github,并且以后会持续更新,如果你先从无到有实现个语言可以关注这个项目。由于 JCScheme 一直在更新中,下面某些设计或链接可以会失效,所以还是建议你关注 Github 上的项目。
预备知识
前缀表达式
由于 JCScheme 极其简单,所以你不需要什么背景知识即可看懂本文,不过你最好了解点 Scheme 语言,如果不了解也没关系,你只需要知道 JCScheme 中的语句使用前缀表达式(也称为波兰表示法),如果你之前没了解过,需要适应下。
# 这是我们常用的中缀表达式
(5 − 6) * 7
# 这就是前缀表达式
* (− 5 6) 7
前缀表达式最明显的一个好处是其操作符的参数可以有不定个,像(+ 1 2 3 4)。
编程语言分类
现在编程语言大致可以分为两种:
- 编译型,该类型语言源代码经由编译器(compiler)转化为机器语言,再由机器运行机器码。像C/C++ 即属于这个范畴。更详细的可以参考深入理解计算机之hello world背后的故事
- 解释型,该类型语言不转化为最终的机器语言,而是由解释器(interpreter)逐行解释执行,像 Python、JavaScript 属于这个范畴, JCScheme 也是这种类型。
由于我这里采用 Java 来实现 JCScheme 的解释器,所以 JCScheme 源代码的执行逻辑是这样的:

可以看到,JCScheme 解释器的主要工作就是将按照自定义语法规则书写的源程序,转化为 Java 代码,之后的事情就由 JVM 来处理了。
JCScheme 解释器
JCScheme解释器主要分为两部分,解析(Parse)和求值(Evaluation):
- 解析:解析源程序,并生成解释器可以理解的中间(Intermediate)结构。这部分包含词法分析,语法分析,语义分析,生成语法树。
- 求值:执行解析阶段得到的中介结构然后得到运行结果。这部分包含作用域,类型系统设计和语法树遍历。
明确了解释的工作后,我们第一步是制定语言的语法,然后进行解析、求值即可。
JCScheme 语法
rlwrap java -jar target/JCScheme-*.jar
>> (* 2 3 4 5)
120
>> (def a 4)
null
>> (def b 5)
null
>> (if (> a b) a b)
5
>> (def max (lambda (a b) (if (> a b) a b)))
null
>> (def c (max a b))
null
>> c
5
从上面可以看出,JCScheme 有以下基本特性:
- 支持整数(Java int实现)与布尔(Java bool实现)、函数三种类型
- 提供
def进行变量定义、if进行逻辑判断、lambda进行函数声明 - 支持整数的
+、-、*、/四种基本算术操作,>、<、=三种比较操作。参数可以为多个 - 更多的特性可以参考ChangeLog
解析过程
解析过程的一般顺序为
词法分析 —-> 语法分析 —-> 语义分析
解析过程最主要的是得到语法树,之后,就可以由后面的求值过程进行求值了。
词法分析
词法分析(lexical analysis)就是将源程序中的字符分割为一个个单词(token,构成源代码最小的单位)。
由于 JCScheme 中使用前缀表示,所以词法解析很简单,两行代码:
1
2
| src = src.replaceAll("\\(", "( ").replaceAll("\\)", " )");
String[] tokens = src.split("\\s+");
|
语法分析
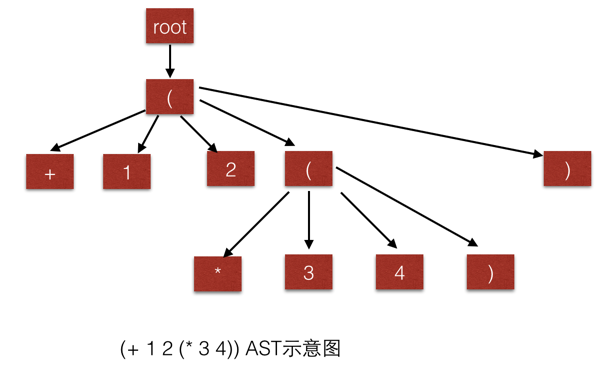
语法分析(Syntactic analysis,也叫Parsing)也就是把词法分析得到的token序列转化为语法树(AST),语法树是程序的中间表示形式,与具体语言无关。JCScheme 采用 Lisp 中经典的S表达式(S-expression)来表示语法树。
AST 本质是一种树,大家可以先想想数据结构中一般都是怎么设计树的存储结构。(其实只要设计的数据结构能够保证获取到当前节点的父节点与子节点就可以了)。下面看看我的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| public class SExpression {
private String value;
private SExpression parent;
private List<SExpression> children;
public SExpression(String value, SExpression parent) {
this.value = value;
this.parent = parent;
this.children = new ArrayList<>();
}
public boolean addChild(SExpression child) {
return this.children.add(child);
}
// 3个 getter 函数省略
// 进行求值的 eval 函数省略,这是重点,后面会单独介绍
@Override
public String toString() {
if (0 == children.size()) {
return value;
} else {
StringBuffer displayBuffer = new StringBuffer(value + " ");
for (SExpression child : children) {
displayBuffer.append(child.toString() + " ");
}
return displayBuffer.toString();
}
}
}
|
解析token序列生产AST的函数是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public static final String START_TOKEN = "(";
public static final String END_TOKEN = ")";
public static SExpression parse(String[] tokens) {
SExpression root = new SExpression("", null);
SExpression parent = root;
for (String token : tokens) {
SExpression newNode = new SExpression(token, parent);
parent.addChild(newNode);
switch (token) {
case Constants.START_TOKEN:
parent = newNode;
break;
case Constants.END_TOKEN:
parent = parent.getParent();
break;
}
}
return root;
}
|
可以看到,每个 AST 根节点是token为空,父节点为 null 的一节点。
这里解析的方法是:
- 每一个token为AST上的一节点,父节点为 parent(初始为root)
- 遇到
( token时,开始创建该节点的子树(通过让这个节点成为 parent 实现) - 遇到
) token时,进行回溯(通过把 parent 赋值为 parent.getParent() 实现)
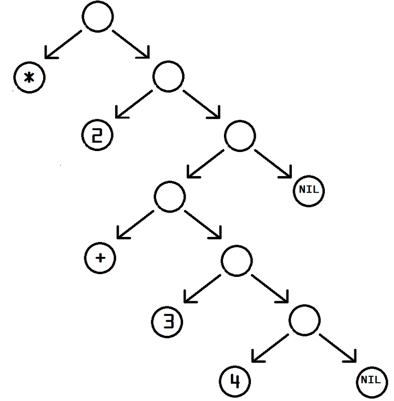
下面看下(+ 1 2 (* 3 4))生成怎样的 SExpression:
 上图最主要的一点就是
> 与左括号相匹配的右括号位于左括号的最后一个孩子节点上(从左到右)。
上图最主要的一点就是
> 与左括号相匹配的右括号位于左括号的最后一个孩子节点上(从左到右)。语义分析
语义分析(Semantic analysis,也叫context sensitive analysis)根据上一步生成的AST,收集源代码的信息,这包括类型校验、变量在使用前是否声明等一系列操作。
因为 JCScheme 中类型比较简单,而且去做语义分析,需要做很多异常处理,有些繁琐,我这里为了简单都忽略了。所以如果你输入的语法有误(比如括号不匹配),那么解释器就会报错,在后面的迭代中会逐步改善这块。
求值过程
经过解析过程,我们已经得到了与具体语言无关的 AST,那么如何进行求值呢,SICP 书中给出答案:eval-apply cycle,如下图
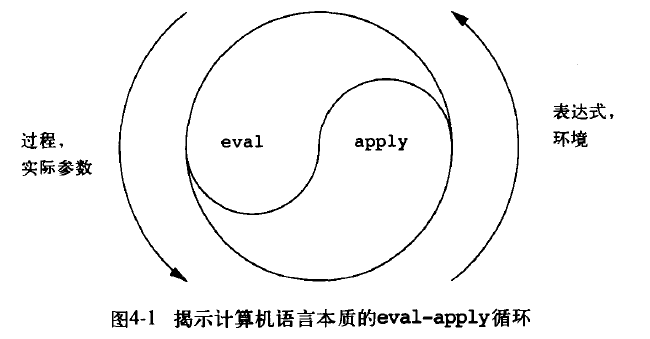 eval、apply 这两个规则描述了求值过程的核心部分,也就是它的基本循环。在这一循环中
> 表达式在环境中的求值被规约到过程对实际参数的应用,而这种应用又被规约到新的表达式在新的环境中的求值,如此下去,直到下降到符号(其值可以在环境中找到)或者基本过程(它们可以直接应用)。
eval、apply 这两个规则描述了求值过程的核心部分,也就是它的基本循环。在这一循环中
> 表达式在环境中的求值被规约到过程对实际参数的应用,而这种应用又被规约到新的表达式在新的环境中的求值,如此下去,直到下降到符号(其值可以在环境中找到)或者基本过程(它们可以直接应用)。在StackOverflow上找到一比较好理解的解释:
- the one that eval is doing, is dealing with the syntactic translation of code to its meaning – but it’s doing almost nothing except dispatching over the expression type
- apply is to call function with values.
- A major enlightenment moment here is to realize that there is a major difference between this eval and apply – the former inherently deals with syntax, but the latter deals with values.
如果你也在读 SICP,可以参考下面的eval、与apply的具体实现,对 Scheme 不了解的可以直接略过。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| (define (eval exp env)
(cond ((self-evaluating? exp) exp)
((variable? exp) (lookup-variable-value exp env))
((quoted? exp) (text-of-quotation exp))
((assignment? exp) (eval-assignment exp env))
((definition? exp) (eval-definition exp env))
((if? exp) (eval-if exp env))
((lambda? exp)
(make-procedure (lambda-parameters exp)
(lambda-body exp)
env))
((begin? exp)
(eval-sequence (begin-actions exp) env))
((cond? exp) (eval (cond->if exp) env))
((application? exp)
(apply (eval (operator exp) env)
(list-of-values (operands exp) env)))
(else
(error "Unknown expression type -- EVAL" exp))))
(define (apply procedure arguments)
(cond ((primitive-procedure? procedure)
(apply-primitive-procedure procedure arguments))
((compound-procedure? procedure)
(eval-sequence
(procedure-body procedure)
(extend-environment
(procedure-parameters procedure)
arguments
(procedure-environment procedure))))
(else
(error
"Unknown procedure type -- APPLY" procedure))))
|
简单来说,eval的主要作用就是理解 AST 的含义,根据其含义进行相应处理,比如赋值语句有其独特的处理方式,if 语句有其独特的处理方式等等。
为了能够让apply进行函数调用求值,需要把 AST 解释为 JCScheme 中内置的类型,而这就是 JCScheme 中eval的主要作用。
类型定义
定义一个基类
1
2
3
| public abstract class SObject {
}
|
然后是整数类型与布尔类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public class SNumber extends SObject{
private int value;
public int getValue() {
return value;
}
public SNumber(int value) {
this.value = value;
}
@Override
public String toString() {
return String.valueOf(value);
}
}
public class SBool extends SObject{
private boolean value;
public boolean getValue() {
return value;
}
public SBool(boolean value) {
this.value = value;
}
@Override
public String toString() {
return String.valueOf(value);
}
}
|
这两个类比较简单,并且注意到没有为其成员变量提供setter函数,这说明这些类型是不可变的。
最后一个比较重要的是函数类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| public class SFunction extends SObject{
List<String> param;
SExpression body;
public SFunction(List<String> param, SExpression body) {
this.param = param;
this.body = body;
}
public SObject apply(SObject... args) {
for(int i = 0; i< args.length; i ++) {
SScope.env.put(param.get(i), args[i]);
}
SObject ret = body.eval();
for(int i = 0; i< args.length; i ++) {
SScope.env.remove(param.get(i));
}
return ret;
}
@Override
public String toString() {
StringBuffer buffer = new StringBuffer("Function : args [");
for(String p : param) {
buffer.append(p + ", ");
}
buffer.append("]\n");
buffer.append("Body :\n");
buffer.append(body.toString());
return buffer.toString();
}
}
|
可以看到,SFunction内部有两个成员变量,用来表示其参数列表与函数体。其中的apply表示函数调用,可以看到无非就是把形式参数与实际参数进行捆绑(现在放到全局环境中,按理说这时应该生成一新环境,后面讲求值过程时会介绍改进版的SFunction),之后调用SExpression的eval方法,得到用内置类型表示的结果。
可以看到,这里的重点又回到eval方法上去了。 JCScheme 的主要复杂点也就算在SExpression的eval方法上,因为它涉及到把SExpression转为内置类型,所以按理说也应该是复杂的。
eval的工作原理最直接的方式就是看源码JCScheme/SExpression.java,这个方法后面会不断完善。
作用域
作用域也可以理解为环境,里面是一系列的 binding,用以保存变量名与其对应值。
在现代编程语言中,作用域一般分为两种:
为了解决在 JCScheme 中函数调用时,新创建环境的父环境应该指向运行时的环境还是声明时的这个问题,我去 Stackoverflow 上提了个问题,对作用域不清楚的可以去看看。
JCScheme 中,一开始只有一个全局作用域,后面我逐渐把这快给完善了,主要是 SScope 类 与 SFunction 类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
| public class SScope {
// 每个环境都指向一个父环境,全局环境父环境为 null
private SScope parent;
private Map<String, SObject> env;
public SScope getParent() {
return parent;
}
public Map<String, SObject> getEnv() {
return env;
}
// 在查找变量时,如何当前 scope 中没有,会沿着环境链,一直找到全局环境中
public SObject findVariable(String var) {
if (env.containsKey(var)) {
return env.get(var);
} else {
SScope p = this.getParent();
while (p != null) {
Map<String, SObject> subEnv = p.getEnv();
if (subEnv.containsKey(var)) {
return subEnv.get(var);
}
p = p.getParent();
}
return null;
}
}
// 当前的环境
public static SScope current = null;
public static Map<String, String> builtinFuncs = new HashMap<String, String>();
public static Map<String, String> builtinKeywords = new HashMap<String, String>();
// 省略一个内置函数、关键字的初始化
// ...
}
public class SFunction extends SObject {
private List<String> param;
private List<SExpression> body;
private SScope scope;
public List<String> getParam() {
return param;
}
// 在声明函数时,传入当前的环境
public SFunction(List<String> param, List<SExpression> body, SScope scope) {
this.param = param;
this.body = body;
this.scope = scope;
}
public SObject apply(SObject... args) {
// 保存函数调用之前的环境,相当于入栈
SScope originScope = SScope.current;
// 创建一个指向函数声明传入的环境的新环境,保存形参与实参的绑定关系。
// 这里构造新环境时用到了声明函数时传入的环境,这点说明了 JCScheme 是静态作用域的
SScope funcScope = new SScope(this.scope);
// 设置当前环境为 新创建的环境,这时所有的求值,都是在其中进行
SScope.current = funcScope;
SObject ret = null;
for (int i = 0; i < args.length; i++) {
SScope.current.getEnv().put(param.get(i), args[i]);
}
if (args.length < param.size()) {
// 实现函数部分调用, currying
List<String> subParam = param.subList(args.length, param.size());
ret = new SFunction(subParam, body, funcScope);
} else {
int bodySize = body.size();
for (int i = 0; i < bodySize - 1; i++) {
body.get(i).eval();
}
// only return last exp
ret = body.get(bodySize - 1).eval();
}
// GC will clean unused scope
// 恢复函数调用之前的环境,相当于出栈
SScope.current = originScope;
return ret;
}
|
不足
经过上面这些工作,JCScheme 已经大功告成了(希望没有bug😊)。但是下面这些点都没有涉及
- 函数的递归调用
匿名函数的直接调用,如((lambda (a b) (+ a b)) 1 2),现在这样的方式是不支持的, 需要先定义个变量,然后在调用,已经支持。函数的部分调用,也就是currying,已经支持
……
后面会逐步添坑,大家可以查看 JCScheme 的 ChangeLog 获取最新进展。
总结
“纸上得来终觉浅,绝知此事要躬行”,最开始时,觉得像 Scheme 语法这么简单的语言实现起来应该不难,做了后才发现眼高手低。比如,我第一次设计SExpression时没有parent这个属性导致了无法正确实现parse函数。以及后面在设计作用域时,分不清楚到底是声明时创建环境还是运行时创建,环境的父环境应该怎么指向,应该指向声明时的环境还是运行时的环境。
不过感触最深应该是这点:动手。在之前学习编程语言,被各种语法类库虐的死去活来,虽然想尝试去实现个自己的语言,但是一直觉得自己能力不够,没敢去尝试,随着不断完善 JCScheme 的功能,对编程语言有了更深刻的认识,真是有种“不入虎穴,焉得虎子”的感觉。
当然,JCScheme 语言只是刚开始,还比较简陋,高手请不要见笑,后面随着学习的深入我会逐步完善。
参考