先来看一个异常信息:
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 51-52: ordinal not in range(128)
相信每个 Python 程序员对上面这个错误都再熟悉不过了,也许你这个问题的根源以及解决方法不是很清楚,那么这篇文章将尝试解答你心中的疑惑。
什么是字符串
Everything you thought you knew about strings is wrong.
计算机中,处理字符串是一个看似简单但及其复杂的问题。推荐我之前写的一文章《字符串,那些你不知道的事》。
Python 2 中的字符类型
Python 2 中有两种字符类型:str与unicode,其区别是:
str is text representation in bytes, unicode is text representation in characters.
字符字面量是str类型,也就是说foo = "你好"这一赋值语句表示的是把你好所对应的二进制字节(这里的字节就是Python解释器读取源文件时读取到的)赋值给变量foo,在 Python 2 中的str类型相当于其他语言的byte类型。
>>> "你好"
'\xe4\xbd\xa0\xe5\xa5\xbd'
unicode对象保存的是字符的code point。在 Python 2 如果想表示 unicode 类型,有下面三种方式:
>>> u"你好"
u'\u4f60\u597d'
>>> "你好".decode("utf8")
u'\u4f60\u597d'
>>> unicode("你好", "utf8")
u'\u4f60\u597d'
Python 2 中的默认编码
sys.getdefaultencoding()可以得到当前 Python 环境的默认编码,Python 2 中为ascii。str与unicode两种字符类型中转化时,如果没有明确指定编码方式,就会用这个默认编码。
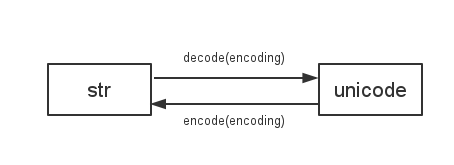
Python 2 中编码问题出现根源
了解了 Python 2 中的两种字符类型以及默认编码,现在就可以分析与编码相关的问题出现的原因了。
在 Python 2 的世界中,很多 API 对这两种字符类型的使用比较混乱,有的可以混用这两种,有的只能使用其中之一,如果在调用 API 时传入了错误的字符类型,Python 2 会自动去转为正确的字符类型,问题就出现在自动转化时用的编码默认是ascii,所以经常会出现UnicodeDecodeError或UnicodeEncodeError错误了。
随着 unicode 的普及,Python 2 中越来越多的 API 使用 unicode 类型的字符串作为参数与返回值,我们在设计 API 时,也尽可能要使用unicode类型。那是不是说,把程序里面的所有字符串都用unicode类型表示,就不会出错了呢?也不尽然,一般有如下准则:
- 在进行文本处理(如查找一个字符串中字符的个数,分割字符串等)时,使用
unicode类型 - 在进行
I/O处理(如,读写磁盘上的文件,打印一个字符串,网络通信等)时,使用str类型
想想也很好理解,因为 Python 2 中的str类型相当于其他语言的byte类型,在进行I/O时操作的是一个个的字节。
实战演练
知道了问题出现的原因,下面举一些常见的与编码相关的错误代码,演示如何正确的使用。
字符串拼接、比较
Python 中字符串在进行拼接与比较时,如果一个是str类型,另一个是unicode类型,那么会把str隐式转为unicode类型。
>>> "%s, %s" % (u"你好", "中国")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
>>> u"你好" > "中国"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
解决方法也很简单,就像上面说的,只要不涉及到I/O操作,一律用unicode类型。
>>> u"%s, %s" % (u"你好", u"中国")
u'\u4f60\u597d, \u4e2d\u56fd'
>>> u"你好" > u"中国"
True
读写文件
内置函数 open(name[, mode[, buffering]]) 可以返回一个文件类型的对象,这里返回的文件对象操作的是str类型的字符,我们可以手动将读到的内容转为unicode类型,但是这里有个问题, 对于多字节编码来说,一个 unicode 字符可能被数目不同的字节表示,如果我们读取了任意固定大小(比如1K,或4K)的数据块,这个数据快的最后几个字节很可能是某个 unicode 字符的前几个字节,我们需要去处理这种异常,一个比较笨的解决方式是把所有数据读取到内存中,然后再去转码,显然这不适合大数据的情况。一个比较好的方法是使用codecs模块的 open(filename, mode='rb', encoding=None, errors='strict', buffering=1)方法,这个方法返回的文件对象操作的是unicode类型的字符,
# cat /tmp/debug.log
你好
>>> with open('/tmp/debug.log') as f:
>>> s = f.read(1) # 读一个字节
>>> print type(s) # str
>>> print s # 无意义的一个符号
>>>
>>> import codecs
>>>
>>> with codecs.open('/tmp/debug.log', encoding='utf-8') as f:
>>> s = f.read(1) # 读一个字符
>>> print type(s) # unicode
>>> print s # 你
如果我们用内置的open进行写文件,必须将unicode字符转为str字符,否则会报错。
>>> with open('/tmp/debug.log', 'w') as f:
>>> f.write(u'你好')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
这个错误很典型,就是因为用默认的ascii去编码你好导致的,显然你好不在ascii字符集内,正确的方式:
>>> with open('/tmp/debug.log', 'w') as f:
>>> f.write(u'你好'.encode('utf-8'))
$ cat /tmp/debug.log
你好
首先需要注意的是 print 在 Python 2 中是一个表达式(和if、return同一级别),而不是一个函数。
print有两种语法形式:
print_stmt ::= "print" ([expression ("," expression)* [","]]
| ">>" expression [("," expression)+ [","]])
默认情况下print打印到标准输出sys.stdout中,可以使用>>后跟一个file-like的对象(具有write方法)进行重定向。例如:
with open('/tmp/debug.log', 'w') as f:
print >> f, '你好'
因为print的参数为str类型的字符,所以在打印到标准输出(一般为终端,例如Mac的iTerm2)时有个隐式转码的过程,这个转码过程默认用的编码在类unix系统上是通过环境变量LC_ALL指定的,在 Windows 系统中,终端默认只能显示256个字符(cp437 指定)。

$ python encode.py UTF-8 你好
$ LC_ALL=C python encode.py
US-ASCII
Traceback (most recent call last):
File “encode.py”, line 21, in
当 `print` 通过重定向,不是打印到标准输出`sys.stdout`时,由于它不知道目标文件的`locale`,所以它又会用默认的`ascii`进行编码了。
$ python encode.py > abc
Traceback (most recent call last):
File “encode.py”, line 21, in
$ cat abc None
$ PYTHONIOENCODING=UTF-8 python encode.py > abc $ cat abc UTF-8 你好
可以看到,在不指定`PYTHONIOENCODING`时,`sys.stdout.encoding`输出`None`了,并且执行`print u"你好"`时报错了。
为了解决打印unicode字符的问题,我们可以通过[codecs.StreamWriter](http://docs.python.org/library/codecs.html#codecs.StreamWriter)来包装一次`sys.stdout`对象。例如:
$ cat encode2.py
coding: utf-8
import codecs import sys
UTF8Writer = codecs.getwriter(‘utf8’) sys.stdout = UTF8Writer(sys.stdout) print u’你好’
$ python encode2.py > abc $ cat abc 你好
需要注意的是,通过`codecs.StreamWriter`包装后的`print`,在输出`str`类型的字符时,会先把这个字符转为`unicode`类型,然后再转为`str`类型,这两个转化过程用的也是默认的`ascii`编码, 所以很有可能又会出错。
$ cat encode3.py
coding: utf-8
import codecs import sys
UTF8Writer = codecs.getwriter(‘utf8’) sys.stdout = UTF8Writer(sys.stdout) print ‘你好’
$ python encode3.py > abc
Traceback (most recent call last):
File “encode3.py”, line 7, in
你可能会问,有没有一劳永逸的解决方法,第三方模块[kitchen](https://pypi.python.org/pypi/kitchen)可以解决这个问题。
$ pip install kitchen $ cat encode4.py
coding: utf-8
import sys from kitchen.text.converters import getwriter UTF8Writer = getwriter(‘utf8’) sys.stdout = UTF8Writer(sys.stdout) print u’你好’ print ‘你好’
$ python encode4.py > abc $ cat abc 你好 你好
可以看到,两种类型的`你好`均被正确重定向到文件中。
### 其他
我上面重点讲解了输入输出时的常见编码错误,其他的编码错误基本上就是 API 参数类型不匹配的参数。自己代码推荐还比较好解决,第三方模块里面的就不好调试了,如果遇到了,只能通过hack的方式来修改第三方模块的源代码了。
一个比较好的建议是,`str`类型的变量名前面用`b_`标示,比如`b_search_hits`,表示返回的搜索结果的类型是`str`。
## never reload(sys)
互联网上比较常见的一个解决编码的方式是:
reload(sys) sys.setdefaultencoding(“utf-8”)
这种解决方式带来的弊远远大于利,下面一个简单的例子:
coding: utf-8
import sys
print “你好” == u"你好"
False
reload(sys) sys.setdefaultencoding(“utf-8”)
print “你好” == u"你好"
True
可以看到,设置默认编码之后,程序的逻辑已经发生了改变,最主要的是,如果我们改变了默认编码,我们所引用的所有第三方模块,也都会改变,就像这里举的例子,程序的逻辑很有可能会改变。关于这个问题的详尽解释,可以参考[Dangers of sys.setdefaultencoding('utf-8')](http://stackoverflow.com/q/28657010/2163429)。
## 总结
通过上面的分析,想象大家对 Python 2 中为什么会出现那么多的编码错误有所了解,根本原因就在于 Python 设计早期混淆了`byte`类型与`str`类型,好歹在 Python 3 解决了这个设计错误。
在另一方面,这里的编码问题对我们理解计算机的运行原理很有帮助,也反映出`copy & paste`的危害,希望大家看了我这篇文章之后,严禁`reload(sys)`这种做法,推荐使用`from __future__ import unicode_literals`来将所有字符字面量表示为 unicode。
如果大家对 Python 2 中的编码问题,还有任何疑问,欢迎留言讨论。
## 参考
- [Should I import unicode_literals?](http://python-future.org/unicode_literals.html)
- [Overcoming frustration: Correctly using unicode in python2](https://pythonhosted.org/kitchen/unicode-frustrations.html)
- [PrintFails](https://wiki.python.org/moin/PrintFails)
- [Unicode HOWTO](https://docs.python.org/2/howto/unicode.html)