1. 前言
以前参加齐鲁软件大师时用过lucene,但是仅仅只是停留在API调用层面上,这次借着看《lucene in action》第二版的机会把与lucene和搜索相关的知识系统整理一遍。以下内容来自lucene in action的翻译加上我自己的理解,如有疑问或错误,请指出,谢谢。
首先来看一个搜索的宏观布局图
图1. 搜索的一般架构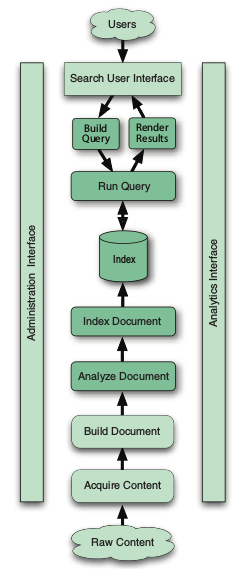 其中深颜色部分是使用Lucene的地方,浅颜色部分需要程序员使用其他工具来完成。
其中深颜色部分是使用Lucene的地方,浅颜色部分需要程序员使用其他工具来完成。
2. Lucene与搜索引擎概貌
Lucene只是一个完整搜索引擎中的一部分,它主要是提供了index(建立索引)与search(搜索)的功能。在具体学习Lucene使用之前,了解搜索引擎的概貌对以后Lucene的学习大有裨益。
1.1 索引相关部分(Components for indexing)
如果我们想在一些文件中搜索某些词组,比如“中国”,最直接的方式就是依次遍历这些文件,对每个文件进行字符串匹配,显然这种方式比较低效,而且不容易扩展,所以我们需要对这些文件中的内容建立索引,在lucene中你可以想象索引是一种加速获取文件中内容的数据结构,一般搜索引擎都采用倒排索引。建立索引一般可以分为一下几步:
1.1.1 获取数据(Acquire Content)
这里的数据根据具体的业务而定,有的在数据库里、有的在doc、pdf等文档里,更一般的是通过网络爬虫(crawler)抓取互联网上的网页数据。
为了获取不同的数据,我们可以使用不同的工具:数据库的话可以直接使用JDBC来读取;doc等文档可以使用Tika等第三库完成;网络爬虫可以使用一些开源的项目:
- Solr——一个Lucene的姐妹项目,可以获取关系型数据库或xml中的数据,通过集成Tika可以获取富文本(rich documents)中的信息。
- Nutch——Lucene另一个姐妹项目,通过一个高扩展性的网络爬虫
- Grub——一个流行的开源网络爬虫,截至本文写作时间,最后一次更新为2013-04-03,用C++编写
1.1.2 创建文档(BUILD DOCUMENT)
数据获取完成后,就需要把这些原始数据转化为搜素引擎理解的单元,这个单元在Lucene中叫做Document,你可以把一个文档、一个网页、一封电子邮件看作一篇文档,而像文章的title、date、author等信息作为Document的Field,上述情形Document比较好区分,但是真实环境中很有可能并不是那么好区分,比如说邮件中的附件,是作为另一个Document与正文的Document相关联还是包含在正文Document的Field里面呢?
有了一个Document以后我们可以很方便的定制搜索结果,比如如果某个Document比较重要,我们可以通过修改Document的boost来实现提高它在搜索中的排名。
Lucene为建立Document提供了一套简单方便的API,后面再介绍。
1.1.3 分析文档(ANALYZE DOCUMENT)
这里主要是指在对原始内容进行分词,因为我们不可能把一整篇文档放到一个Field中,在Lucene中每个分词后的结果称为token,英文中还稍微简单一些,可以直接通过空格键区分,但在非中文环境中,比如我们汉语,分词是个比较难的问题,但网上免费的分词器也有不少,像IKAnalyzer、ICTCLAS、庖丁解牛分词器,不过貌似商业用的话,像百度、淘宝这样的,一般都是自己写的。
1.1.4 建立索引
完成上面这些以后,我们就可以使用lucene提供的api建立索引了。
1.2 搜索相关部分(Components for searching)
搜索就是在索引中查询用户输入的关键字的过程。评价搜索的质量有两个指标
- 准确率(precision)——指在搜索结果中过滤掉无关Document的程度(measures how well the search system find relevant documents)
- 召回率(recall)——指在搜索结果中Document与用户输入的关键字的相关性(measures how well the system filters out the irrelevant documents)
通过Lucene的contrib中的benchmark可以检测我们搜索系统中的准确率与召回率。
1.2.1 搜索接口(SEARCH USER INTERFACE)
要想搜索首先需要提供一个搜索界面,这里一般是指的网页应用中,这个是很重要的一步,现在都强调用户体验,如果你的搜索界面让用户感到厌烦,用户怎么可以有使用你产品的欲望呢。
搜索界面主要是强调简洁,像百度、google那样,在搜索结果页面中,Document结果的展示也必须恰到好处,不能显示太多的文字,也不能显示太少的文字。除此之外,用户必须可以很方便的找到“相关搜索”、“结果过滤”等功能,如果你对搜索结果进行了定制(通过修改Document的boost),必须让用户知道,而且必须提供一个关闭定制的选项。
1.2.2 创建Query(BUILD QUERY)
用户输入的关键字在会被Lucene处理为一个Query类的对象,Query有很多子类,可以实现逻辑上的“与或非”的BooleanQuery,比如我们搜索时可以收入下面的关键字“java & 书籍”, 说明我们想要搜索的是与java有关的书籍。lucene中有各种Query,lucene为了方便用户使用,提供了一个QueryParser对象,它可以自动解析用户输入的关键字转为相应的query对象
1.2.3 搜索Query(SEARCH QUERY)
当Query构建好后,就可以进行搜索了。一般有三种实用的搜索模型:
- 逻辑模型(Pure Boolean model)——每个Document要么包含这个查询的内容,要么不包含,就这两种情况。在这种模型下,包含查询内容的Documents没有相关性的强弱之分,所以这种情况下也就没有办法为结果排序。
- 向量空间模型(Vector space model)——Query对象与Document对象都用高维向量表示,没一个term就是一个维度。通过计算query与document对象的距离(余弦定理)可以得到Document相关性的强弱,这样也就可以为结果排序了。
- 概率模型(Probabilistic model)——通过全概率方法计算每个Document符合查询query的概率来表示相关性。(In this model, you compute the probability that a document is a good match to a query using a full probabilistic approach)
1.2.4 结果展示(RENDER RESULTS)
在Lucene中,结合了逻辑模型与向量空间模型来匹配query,得到了匹配的Document对象后,你需要负责把结果友好的展现出来,这一步决定了用户的体验程序好坏。
1.3 搜索的其他方面(The rest of the search application)
完成了建立索引与搜索这两大模块后,还有一些工作要去做,这些工作一般都存在于web项目中。第一,需要提供一个管理界面,用来跟踪应用的状态,配置应用的不同部分,开启与关闭服务器等。第二,还必须要包括分析工具,可以你就可以知道用户都热衷于搜索那些关键词,这样你就能更好的维护你的应用。第三,一个健壮的搜索引擎一般都支持扩展性(scaling)。下面对上面说的这三点分别进行阐述。
1.3.1 管理员界面(ADMINISTRATION INTERFACE)
现在的搜索引擎一般都是个负责的系统,有许多部分都需要配置才能使系统发挥最好的性能。如果你用爬虫抓取网页,你可以通过管理界面给出需要爬的根网页,爬的范围、速度等参数。
Lucene有许多可以配置的地方。比如RAM buffer的大小,提交修改索引的频率与优化索引中的删除项等等不一而足。
1.3.2 分析界面(ANALYTICS INTERFACE)
通过对用户搜索行为的学习与分析,系统能够提供更好的用户体验。在与Lucene相关的分析一般包括以下几点:
- 不同种类型的query,比如single term,phrase,boolean query的使用频率
- 哪些query的搜索结果比较少(Queries that hit low relevance)
- 对于哪些query用户没去再次点击结果
- 搜索的时间
1.3.3 扩展(scaling)
搜索引擎的扩展一般包括两个方面:
- 索引数据的扩展
- 用户并发搜索的扩展
可扩展是一个系统很重要的特性,想想如果提供搜索的服务器只有一台,那么如果该服务器fail了,那整个搜索就没法用了,这是不能忍受了,这时往往需要用两台或多台服务器来提供搜索服务。多台机器同时提供搜索还是比较困难的,比如,在用户输入一个query后,系统需要有一个front-end来将这个query转发给后台的服务器,由于各个服务器是孤立的,每个服务器在将搜索结果返回时如何排序是个大问题。
Lucene没有为扩展做专门的处理,需要用户自己解决。但是在用户自己动手实现scaling之前,可以先参照开源世界中的Solr与Nutch,这两个都是lucene的姐妹项目,除此之外还有Katta与ElasticSearch,他们都为搜索提供了很好的扩展性。
PS: 在本文写作期间,katta貌似已经停止了更新,最后一次更新是在2010年,ElasticSearch则比较活跃,而且在found.no可以找到很详细的参考的资料。