上周把HashMap、TreeMap这两个Map体系中比较有代表性的类介绍完了,大家应该也能体会到,如果该类所对应的数据结构与算法掌握好了,再看这些类的源码真是太简单不过了。
其次,我希望大家能够触类旁通,比如我们已经掌握了HashMap的原理,我们可以推知HashSet的内部实现
HashSet 内部用一个HashMap对象存储数据,更具体些,只用到了key,value全部为一dummy对象。
HashSet这个类太简单了,我不打算单独写文章介绍。今天介绍个比较实用的类——LinkedHashMap。
本文源码分析基于Oracle JDK 1.7.0_71,请知悉。
$ java -version
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b14)
Java HotSpot(TM) 64-Bit Server VM (build 24.71-b01, mixed mode)
签名
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
可以看到,LinkedHashMap是HashMap的一子类,它根据自身的特性修改了HashMap的内部某些方法的实现,要想知道LinkedHashMap具体修改了哪些方法,就需要了解LinkedHashMap的设计原理了。
设计原理
双向链表
LinkedHashMap是key键有序的HashMap的一种实现。它除了使用哈希表这个数据结构,使用双向链表来保证key的顺序
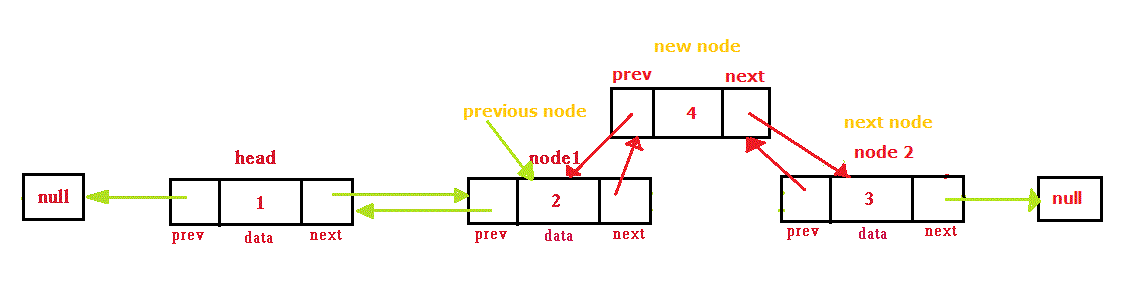

LinkedHashMap中采用的这种环型双向链表,环型双向链表的用途比较多,感兴趣可以看这里:
双向链表这种数据结构,最关键的是保证在增加节点、删除节点时不要断链,后面在分析LinkedHashMap具体代码时会具体介绍,这里就不赘述了。
LinkedHashMap 特点
一般来说,如果需要使用的Map中的key无序,选择HashMap;如果要求key有序,则选择TreeMap。
但是选择TreeMap就会有性能问题,因为TreeMap的get操作的时间复杂度是O(log(n))的,相比于HashMap的O(1)还是差不少的,LinkedHashMap的出现就是为了平衡这些因素,使得
能够以
O(1)时间复杂度增加查找元素,又能够保证key的有序性
此外,LinkedHashMap提供了两种key的顺序:
- 访问顺序(access order)。非常实用,可以使用这种顺序实现LRU(Least Recently Used)缓存
- 插入顺序(insertion orde)。同一key的多次插入,并不会影响其顺序
源码分析
首先打开eclipse的outline面版看看LinkedHashMap里面有那些成员

构造函数
1 //accessOrder为true表示该LinkedHashMap的key为访问顺序
2 //accessOrder为false表示该LinkedHashMap的key为插入顺序
3 private final boolean accessOrder;
4
5 public LinkedHashMap(int initialCapacity, float loadFactor) {
6 super(initialCapacity, loadFactor);
7 //默认为false,也就是插入顺序
8 accessOrder = false;
9 }
10 public LinkedHashMap(int initialCapacity) {
11 super(initialCapacity);
12 accessOrder = false;
13 }
14 public LinkedHashMap() {
15 super();
16 accessOrder = false;
17 }
18 public LinkedHashMap(Map<? extends K, ? extends V> m) {
19 super(m);
20 accessOrder = false;
21 }
22 public LinkedHashMap(int initialCapacity,
23 float loadFactor,
24 boolean accessOrder) {
25 super(initialCapacity, loadFactor);
26 this.accessOrder = accessOrder;
27 }
28
29 /**
30 * Called by superclass constructors and pseudoconstructors (clone,
31 * readObject) before any entries are inserted into the map. Initializes
32 * the chain.
33 */
34 @Override
35 void init() {
36 header = new Entry<>(-1, null, null, null);
37 //通过这里可以看出,LinkedHashMap采用的是环型的双向链表
38 header.before = header.after = header;
39 }
LinkedHashMap.Entry
1 private static class Entry<K,V> extends HashMap.Entry<K,V> {
2 // These fields comprise the doubly linked list used for iteration.
3 //每个节点包含两个指针,指向前继节点与后继节点
4 Entry<K,V> before, after;
5
6 Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
7 super(hash, key, value, next);
8 }
9
10 /**
11 * Removes this entry from the linked list.
12 */
13 //删除一个节点时,需要把
14 //1. 前继节点的后继指针 指向 要删除节点的后继节点
15 //2. 后继节点的前继指针 指向 要删除节点的前继节点
16 private void remove() {
17 before.after = after;
18 after.before = before;
19 }
20
21 /**
22 * Inserts this entry before the specified existing entry in the list.
23 */
24 //在某节点前插入节点
25 private void addBefore(Entry<K,V> existingEntry) {
26 after = existingEntry;
27 before = existingEntry.before;
28 before.after = this;
29 after.before = this;
30 }
31
32 /**
33 * This method is invoked by the superclass whenever the value
34 * of a pre-existing entry is read by Map.get or modified by Map.set.
35 * If the enclosing Map is access-ordered, it moves the entry
36 * to the end of the list; otherwise, it does nothing.
37 */
38 void recordAccess(HashMap<K,V> m) {
39 LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
40 // 如果需要key的访问顺序,需要把
41 // 当前访问的节点删除,并把它插入到双向链表的起始位置
42 if (lm.accessOrder) {
43 lm.modCount++;
44 remove();
45 addBefore(lm.header);
46 }
47 }
48
49 void recordRemoval(HashMap<K,V> m) {
50 remove();
51 }
52 }
为了更形象表示双向链表是如何删除、增加节点,下面用代码加图示的方式
删除节点

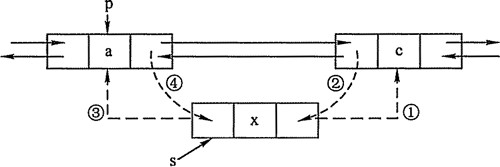
1 private void addBefore(Entry<K,V> existingEntry) {
2 after = existingEntry; //相当于上图中的操作 1
3 before = existingEntry.before; //相当于上图中的操作 3
4 before.after = this; //相当于上图中的操作 4
5 after.before = this; //相当于上图中的操作 2
6 }
知道了增加节点的原理,下面看看LinkedHashMap的代码是怎么实现put方法的
1 /**
2 * This override alters behavior of superclass put method. It causes newly
3 * allocated entry to get inserted at the end of the linked list and
4 * removes the eldest entry if appropriate.
5 */
6 void addEntry(int hash, K key, V value, int bucketIndex) {
7 super.addEntry(hash, key, value, bucketIndex);
8
9 // Remove eldest entry if instructed
10 Entry<K,V> eldest = header.after;
11 //如果有必要移除最老的节点,那么就移除。LinkedHashMap默认removeEldestEntry总是返回false
12 //也就是这里if里面的语句永远不会执行
13 //这里removeEldestEntry主要是给LinkedHashMap的子类留下的一个钩子
14 //子类完全可以根据自己的需要重写removeEldestEntry,后面我会举个现实中的例子🌰
15 if (removeEldestEntry(eldest)) {
16 removeEntryForKey(eldest.key);
17 }
18 }
19 /**
20 * This override differs from addEntry in that it doesn't resize the
21 * table or remove the eldest entry.
22 */
23 void createEntry(int hash, K key, V value, int bucketIndex) {
24 HashMap.Entry<K,V> old = table[bucketIndex];
25 Entry<K,V> e = new Entry<>(hash, key, value, old);
26 table[bucketIndex] = e;
27 //这里把新增的Entry加到了双向链表的header的前面,成为新的header
28 e.addBefore(header);
29 size++;
30 }
31 /**
32 * Returns <tt>true</tt> if this map should remove its eldest entry.
33 * This method is invoked by <tt>put</tt> and <tt>putAll</tt> after
34 * inserting a new entry into the map. It provides the implementor
35 * with the opportunity to remove the eldest entry each time a new one
36 * is added. This is useful if the map represents a cache: it allows
37 * the map to reduce memory consumption by deleting stale entries.
38 *
39 * <p>Sample use: this override will allow the map to grow up to 100
40 * entries and then delete the eldest entry each time a new entry is
41 * added, maintaining a steady state of 100 entries.
42 * <pre>
43 * private static final int MAX_ENTRIES = 100;
44 *
45 * protected boolean removeEldestEntry(Map.Entry eldest) {
46 * return size() > MAX_ENTRIES;
47 * }
48 * </pre>
49 *
50 * <p>This method typically does not modify the map in any way,
51 * instead allowing the map to modify itself as directed by its
52 * return value. It <i>is</i> permitted for this method to modify
53 * the map directly, but if it does so, it <i>must</i> return
54 * <tt>false</tt> (indicating that the map should not attempt any
55 * further modification). The effects of returning <tt>true</tt>
56 * after modifying the map from within this method are unspecified.
57 *
58 * <p>This implementation merely returns <tt>false</tt> (so that this
59 * map acts like a normal map - the eldest element is never removed).
60 *
61 * @param eldest The least recently inserted entry in the map, or if
62 * this is an access-ordered map, the least recently accessed
63 * entry. This is the entry that will be removed it this
64 * method returns <tt>true</tt>. If the map was empty prior
65 * to the <tt>put</tt> or <tt>putAll</tt> invocation resulting
66 * in this invocation, this will be the entry that was just
67 * inserted; in other words, if the map contains a single
68 * entry, the eldest entry is also the newest.
69 * @return <tt>true</tt> if the eldest entry should be removed
70 * from the map; <tt>false</tt> if it should be retained.
71 */
72 protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
73 return false;
74 }
上面是LinkedHashMap中重写了HashMap的两个方法,当调用put时添加Entry(新增Entry之前不存在)整个方法调用链是这样的:
LinkedHashMap.put->LinkedHashMap.addEntry->HashMap.addEntry->LinkedHashMap.createEntry
有了这个调用链,再结合上面createEntry方法中的注释,就可以明白如何在添加Entry保证双向链表不断链的了。
实战:LRU缓存
上面已经介绍了,利用访问顺序这种方式可以实现LRU缓存,正好最近在用flume向hadoop传数据,发现里面hdfs sink里面就用到了这种思想。
如果你不了解flume、hdfs、sink等这些概念,也不要紧,也不会影响阅读下面的代码,相信我😊。
1 /*
2 * Extended Java LinkedHashMap for open file handle LRU queue.
3 * We want to clear the oldest file handle if there are too many open ones.
4 */
5 private static class WriterLinkedHashMap
6 extends LinkedHashMap<String, BucketWriter> {
7
8 private final int maxOpenFiles;
9
10 public WriterLinkedHashMap(int maxOpenFiles) {
11 //这里的第三个参数为true,表示key默认的顺序为访问顺序,而不是插入顺序
12 super(16, 0.75f, true); // stock initial capacity/load, access ordering
13 this.maxOpenFiles = maxOpenFiles;
14 }
15
16 @Override
17 protected boolean removeEldestEntry(Entry<String, BucketWriter> eldest) {
18 if (size() > maxOpenFiles) {
19 // If we have more that max open files, then close the last one and
20 // return true
21 try {
22 eldest.getValue().close();
23 } catch (IOException e) {
24 LOG.warn(eldest.getKey().toString(), e);
25 } catch (InterruptedException e) {
26 LOG.warn(eldest.getKey().toString(), e);
27 Thread.currentThread().interrupt();
28 }
29 return true;
30 } else {
31 return false;
32 }
33 }
34 }
可以看到,这里的WriterLinkedHashMap主要是重写了removeEldestEntry方法,我们上面介绍了,在LinkedHashMap中,这个方法总是返回false,在这里设定了一个阈值maxOpenFiles,如果打开的文件数超过了这个阈值,就返回true,即把之前最不经常访问的节点给删除掉,达到释放资源的效果。
更高效的LinkedHashIterator
由于元素之间用双向链表连接起来了,所以在遍历元素时只需遍历双向链表即可,这比HashMap中的遍历方式要高效。
1 private abstract class LinkedHashIterator<T> implements Iterator<T> {
2 Entry<K,V> nextEntry = header.after;
3 Entry<K,V> lastReturned = null;
4
5 /**
6 * The modCount value that the iterator believes that the backing
7 * List should have. If this expectation is violated, the iterator
8 * has detected concurrent modification.
9 */
10 int expectedModCount = modCount;
11 //由于采用环型双向链表,所以可以用header.after == header 来判断双向链表是否为空
12 public boolean hasNext() {
13 return nextEntry != header;
14 }
15
16 public void remove() {
17 if (lastReturned == null)
18 throw new IllegalStateException();
19 if (modCount != expectedModCount)
20 throw new ConcurrentModificationException();
21
22 LinkedHashMap.this.remove(lastReturned.key);
23 lastReturned = null;
24 expectedModCount = modCount;
25 }
26
27 Entry<K,V> nextEntry() {
28 if (modCount != expectedModCount)
29 throw new ConcurrentModificationException();
30 if (nextEntry == header)
31 throw new NoSuchElementException();
32 Entry<K,V> e = lastReturned = nextEntry;
33 //在访问下一个节点时,直接使用当前节点的后继指针即可
34 nextEntry = e.after;
35 return e;
36 }
37 }
除了LinkedHashIterator利用了双向链表遍历的优势外,下面的两个方法也利用这个优势加速执行。
1 /**
2 * Transfers all entries to new table array. This method is called
3 * by superclass resize. It is overridden for performance, as it is
4 * faster to iterate using our linked list.
5 */
6 @Override
7 void transfer(HashMap.Entry[] newTable, boolean rehash) {
8 int newCapacity = newTable.length;
9 for (Entry<K,V> e = header.after; e != header; e = e.after) {
10 if (rehash)
11 e.hash = (e.key == null) ? 0 : hash(e.key);
12 int index = indexFor(e.hash, newCapacity);
13 e.next = newTable[index];
14 newTable[index] = e;
15 }
16 }
17
18
19 /**
20 * Returns <tt>true</tt> if this map maps one or more keys to the
21 * specified value.
22 *
23 * @param value value whose presence in this map is to be tested
24 * @return <tt>true</tt> if this map maps one or more keys to the
25 * specified value
26 */
27 public boolean containsValue(Object value) {
28 // Overridden to take advantage of faster iterator
29 if (value==null) {
30 for (Entry e = header.after; e != header; e = e.after)
31 if (e.value==null)
32 return true;
33 } else {
34 for (Entry e = header.after; e != header; e = e.after)
35 if (value.equals(e.value))
36 return true;
37 }
38 return false;
39 }
总结
通过这次分析LinkedHashMap,我发现JDK里面的类设计确实巧妙,父类中很多为空的方法,看似无用,其实是为子类留的一个钩子,子类可以根据需要重写这个方法,像LinkedHashMap就重写了init方法,这个方法在HashMap中的实现为空。
其次我还想强调下一些基础数据结构与算法的重要性,语言现在很多,火的也多,我们不可能一一去学习,语法说白了就是一系列规则(也可以说是语法糖衣),不同的语言创建者所定的规则可能千差万别,但是他们所基于的数据结构与算法肯定是统一的。去伪存真,算法与数据结构才是我们真正需要学习的。
最近在看Y_combinator,函数式编程中最迷人的地方,希望自己完全理解后再与大家分享。Stay Tuned!