最近在看《Dive Into Python 3》,第四章讲了字符串相关知识,看后才发现,字符串远比我们想象的要复杂多。就像该书所说的
Everything you thought you knew about strings is wrong.
是的,我之前对字符串的理解都是错的。
也许你会诧异,字符串有什么难的,即便遇到乱码的情况随便 Google 下就能找到解决方法,但是这样你不觉得有种被动的感觉嘛,我觉得和学习任何东西一样,学习编程首要是学习其思想,知道某事物为什么(why)要这么做,至于如何做(how)那只是前辈们提出的解决方案,我们可以参考,随便掌握下来。
本文下面首先讲解字符、字符串、编码、ASCII、Unicode、UTF-8 等一些基本概念,然后会介绍在使用计算机时是如何如编码打交道的,也就是实战部分。 希望大家在阅读完本文后,都能对 string 有一全新的认识。
为什么需要字符编码
当我们谈到字符串(string或text)时,你可能会想到“计算机屏幕上的那些字符(characters)与符号(symbols)”,你正在阅读的文章,无非也是由一串字符组成的。但是你也许会发现,你无法给“字符串”一明确定义,但是我们就是知道,就像给你一个苹果,你能说出其名字,但是不能给出准确定义一样。这个问题先放一放,后面我再解释。
我们知道,计算机并不能直接处理操作字符与符号,它只认识 0、1 这两个数字,所以如果想让计算机显示各种各样的字符与符号,就必须定义它们与数字的一一映射关系,也就是我们所熟知的字符编码(character encoding)。你可简单的认为,字符编码为计算机屏幕上显示的字符与这些字符保存在内存或磁盘中的形式提供了一种映射关系。字符编码纷繁复杂,有些专门为特定语言优化,像针对简体中文的编码就有 EUC-CN,HZ;针对日文的EUC-JP,针对英文的 ASCII;另一些专门用于多语言环境,像后面要讲到的 UTF-8。
我们可以把字符编码看作一种解密密钥(decryption key),当我们收到一段字节流时,无论来自文件还是网络,如果我们知道它是“文本(text)”,那么我们就需要知道采用何种字符编码来解码这些字节流,否则,我们得到的只是一堆无意义的符号,像 ������。
单字节编码
计算机最早起源于以英文为母语的美国,英文中的符号比较少,用七个二进制位就足以表示,现在最常见也是最流行的莫过于 ASCII 编码,该编码使用 0 到 127 之间的数字来存储字符(65表示“A”,97表示“a”)。
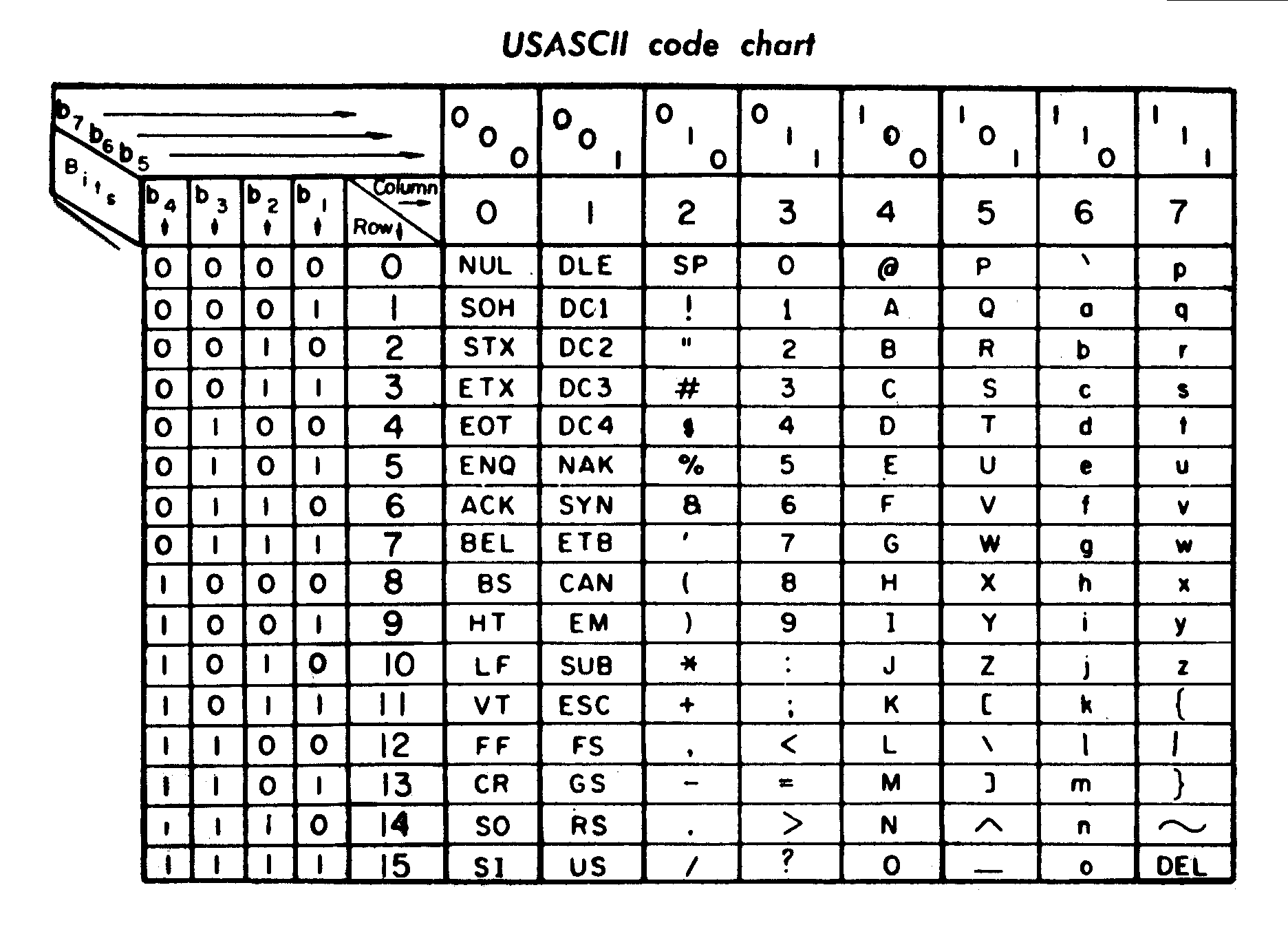

随着时间的推进,计算机的使用范围扩展到西方欧洲国家,像法国🇫🇷、西班牙🇪🇸,德国🇩🇪等,它们这些国家的字母比英文要多。所以为了表示这些国家的语言,也需要借助最高位扩展 ASCII 编码。但由于没有统一的标准,有些地方用 130 表示 é,有些地方表示为 Hebrew letter Gimel ג。在这些语言中,使用最广的是 CP-1252 编码,也称为 Windows-1252 编码,因为在 Windows 在 1.0 时就使用了该编码,随着 Windows 的普及,大家就沿用了 Windows-1252 的说法。

ISO-8859-1
既然说到了 Windows-1252,那么就不能不提它与 ISO-8859-1 的关系,我相信大家对 ISO-8859-1 这个编码肯定很熟悉,我还记得第一次用 Dreamweaver 写 HTML 时,其 HTML 模板中默认编码就是 ISO-8859-1,还有一个比较常见的场景是在 mysql 中,mysql 的默认编码为 latin-1,这其实是 ISO-8859-1 的一个别名而已。
ISO-8859-1 是早期 8 位编码方案的一种,是 ISO/IEC 8859 编码系列的一种, 第一版发布于 1987 年。它主要是针对西欧国家设计,现在大多数流行的 8 位编码方案都以它为基础,这其中就包括 Windows-1252。
Windows-1252 与 ISO-8859-1 的主要不同在于 0x80 到 0x9F 之间的字符,在 ISO-8859-1 中为控制字符(control characters),在 Windows-1252 中为可打印字符(printable characters)。
在 HTTP 协议中,以text/开头的 MIME 类型的文件默认编码为 ISO-8859-1,但是由于控制字符在文件中用处不大,所以大多数客户端程序用 Windows-1252 来解码,这也就是它们之间经常混淆的主要原因。
字符集 vs 字符编码
在介绍完 ASCII 之后,需要强调一个很重要但被大多数人都忽略的一个概念问题。
我们平时说的 ASCII 其实有两个含义,一个是 ASCII 字符集,另一个是 ASCII 编码。
ASCII 字符集只是定义了字符与字符码(character code,也称 code point 代码点)的对应关系。也就是说这一层面只是规定了字符
A用 65 表示,至于这个 65 在内存或硬盘中怎么表示,它不管,那是 ASCII 编码做的事。
ASCII 编码规定了用 7 个二进制位来保存 ASCII 字符码,即定义了字符集的
存储形式。
说到这里你也许会问,那既然用 7 个二进制位就能够表示所有 ASCII 字符码了,为什么现在一个字节是 8 位,而不是 7 位呢,这不是浪费吗?
其实这是早期设计者有意而为之:
7 位表示 ASCII 字符码,剩下 1 位为 Parity bit,也称为校验位,用以检查数据的正确性。
关于数据校验,我这里不打算展开讲,感兴趣的可以参考 Error detection and correction。
为了让大家更清楚的明白这两者以及相关概念的关系,我画了图,便于大家理解。
Character 字符。即我们看到的单个符号,像“A”、“啊”等Code point 代码点。一个无符号数字,通常用16进制表示。代码点与字符的一一对应关系称为字符集(Character Set),这种对应关系肯定不止一种,也就导致了不同字符集的出现,像 ASCII、ISO-8859-1、GB2312、GBK、Unicode 等。Bytes 二进制字节。其含义为代码点在内存或磁盘中的表示形式。代码点与二进制字节的一一对应关系称为编码(Encoding),当然这种对应关系也不是唯一的,所以编码也有很多种,像 ASCII、ISO-8859-1、ENC-CN、GBK、UTF-8等。
上面这个图基本把我们平时经常混淆的概念清晰地区分开了,大家一定要充分理解并牢记于心。
多字节编码
多字节编码主要用于我们亚洲国家,像中文(Chinese),日文(Japanese),韩文(Korean)(业界一般称为 CJK)等象形(表意)文字(ideograph-based language),字符数量比较多,1 个字节是放不下的,所以需要更多的字节来进行字符的编码。
ISO/IEC 2022 标准为多字节编码制定了一套标准,主要有下面两个方面:
- 一个编码系统里面可以表示多种字符集
- 一个编码系统既可以在 7 位编码系统中表示所有字符集,也可以在 8 位编码系统表示所有字符集
为了能够表示多种字符集 ISO/IEC 2022 引入了escape sequences,也就是我们中文里面说的“转义字符”的意思;为了能够兼容之前的 7 位编码系统,像 ASCII,实现 ISO/IEC 2022 标准的编码系统一般都是变长编码。
GB2312
GB2312 是我国国家标准总局在1980年发布一套遵循 ISO/IEC 2022 标准的字符集,在 GB2312 中,字符码一般称为区位码,由于该字符集需要兼容 ASCII 字符集,所以它只能一个字节中的 7 位,剩下 1 位用于区分,比如可以通过最高位为 1 表示 GB2312 字符集,为 0 表示 ASCII 字符集。
GB2312 使用两个字节来表示字符码,最多可以表示 94 * 94 个字符,但是 GB2312 并没有全部使用,留了一部分方便后面扩展用。
实现 GB2312 字符集的编码主要是 EUC-CN,该编码与 ASCII 编码兼容。
我们平时说的 GB2312 编码其实就是指的 EUC-CN 编码,这一点需要明白。
GBK
GBK 字符集是对 GB2312 字符集的扩展,GBK 并没有一个官方标准,现在使用最广的标准是微软在 Windows 95 中实现的版本——CP936 编码。
GBK 也使用两个字节来表示字符码,94 * 94 的区位码分布可以参考下面这个图,截自 Wikipedia
{kind=link}
同 GB2312 一样,我们平时说的 GBK 编码其实就是指的 CP936 编码。
除了我们中国的 GB* 系统字符集以外,日本、韩国各有各的字符集标准,虽然都是基于 ISO/IEC 2022,但是具体的表示方式千差万别,比如 1601 在 GB2312 中表示“啊”,但在日韩就不知道表示什么含义了。
所以,我们需要一种囊括世界上所有字符的一套字符集,在该字符集中,字符码与字符一一对应,比如字符码 0x41 表示英文字母A,在任何国家都表示A,即使该国家没有这个字符。解决这个问题的是现在最流行的一套字符集——Unicode。
Unicode
Unicode 的全称是 universal character encoding,中文一般翻译为“统一码、万国码、单一码”。

在 Unicode 中字符码称为 code point,用 4 个字节来表示,这么做主要是为了涵盖世界上所有的字符。写法一般为U+XXXX,XXXX 为用 16 进制表示的数字。比如,U+0041表示A。
Unicode 的存储形式
Unicode 的存储形式一般称为UTF-*编码,其中 UTF 全称为 Unicode Transformation Format,常见的有:
UTF-32
UTF-32 编码是 Unicode 最直接的存储方式,用 4 个字节来分别表示 code point 中的 4 个字节,也是 UTF-*编码家族中唯一的一种定长编码(fixed-length encoding)。UTF-32 的好处是能够在O(1)时间内找到第 N 个字符,因为第 N 个字符的编码的起点是 N*4 个字节,当然,劣势更明显,四个字节表示一个字符,别说以英文为母语的人不干,我们中国人也不干了。
UTF-16
UTF-16 最少可以采用 2 个字节表示 code point,需要注意的是,UTF-16 是一种变长编码(variable-length encoding),只不过对于 65535 之内的 code point,采用 2 个字节表示而已。如果想要表示 65535 之上的字符,需要一些 hack 的手段,具体可以参考wiki UTF-16#U.2B10000_to_U.2B10FFFF。很明显,UTF-16 比 UTF-32 节约一半的存储空间,如果用不到 65535 之上的字符的话,也能够在O(1)时间内找到第 N 个字符。
UTF-16 与 UTF-32 还有一个不明显的缺点。我们知道不同的计算机存储字节的顺序是不一样的,这也就意味着
U+4E2D在 UTF-16 可以保存为4E 2D,也可以保存成2D 4E,这取决于计算机是采用大端模式还是小端模式,UTF-32 的情况也类似。为了解决这个问题,引入了 BOM (Byte Order Mark),它是一特殊的不可见字符,位于文件的起始位置,标示该文件的字节序。对于 UTF-16 来说,BOM 为U+FEFF(FF 比 FE 大 1),如果 UTF-16 编码的文件以FF FE开始,那么就意味着其字节序为小端模式,如果以FE FF开始,那么就是大端模式。 其他 UTF-* 编码的 BOM 可以参考 Representations of byte order marks by encoding。
UTF-8
UTF-16 对于以英文为母语的人来说,还是有些浪费了,这时聪明的人们(准确说是Ken Thompson与Rob Pike)又发明了另一个编码——UTF-8。在 UTF-8 中,ASCII 字符采用单字节。其实,UTF-8 前 128 个字符与 ASCII 字符编码方式一致;扩展的拉丁字符像ñ、ö等采用2个字节存储;中文字符采用 3 个字符存储,使用频率极少字符采用 4 个字节存储。由此可见,UTF-8 也是一种变长编码(variable-length encoding)。
UTF-8 的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 code point。因此对于英语字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号,第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 code point。

通过上面这两个规则,UTF-8 就不存在字节顺序在大小端不同的情况,所以用 UTF-8 编码的文件在任何计算机中保存的字节流都是一致的,这是其很重要一优势;UTF-8 的另一大优势在于对 ASCII 字符超节省空间,存储扩展拉丁字符与 UTF-16 的情况一样,存储汉字字符比 UTF-32 更优。
UTF-8 的一劣势是查找第 N 个字符时需要O(N) 的时间,也就是说,字符串越长,就需要更长的时间来查找其中的每个字符。其次是在对字节流解码、字符编码时,需要遵循上面两条规则,比 UTF-16、UTF-32 略麻烦。
随着互联网的兴起,UTF-8 是逐渐成为使用范围最广的编码方案。下图为 Google 在 2010 年初做的统计(链接需翻墙)
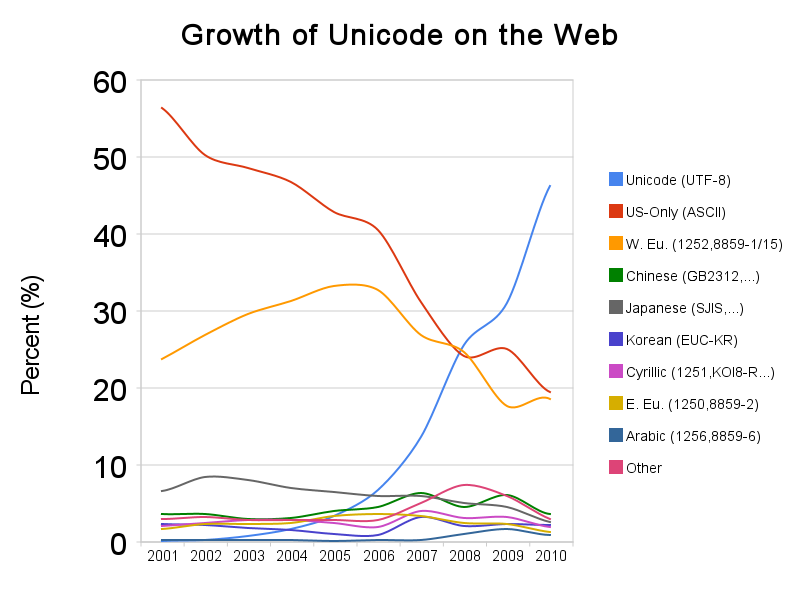
UCS
我们在互联网上查找编码相关资料时,经常会看到UCS-2、UCS-4编码,它们和UTF-*编码家族是什么关系呢?要想理清它们之间的关系,需要先弄清楚,什么是 UCS。
UCS 全称是 Universal Coded Character Set,是由 ISO/IEC 10646定义的一套标准字符集,是很多字符编码的基础,UCS 中大概包含 100,000 个抽象字符,每一个字符都有一唯一的数字编码,称为 code point。
在19世纪八十年代晚期,有两个组织同时在 UCS 的基础上开发一种与具体语言无关的统一的编码方案,这两个组织分别是 IEEE 与 Unicode Consortium,为了保持这两个组织间编码方案的兼容性,两个组织尝试着合作。早期的两字节编码方案叫做“Unicode”,后来改名为“UCS-2”,在研发过程发,发现 16 位根本不能够囊括所有字符,于是 IEEE 引入了新的编码方案——UCS-4 编码,这种编码每个字符需要 4 个字节,这一行为立刻被 Unicode Consortium 制止了,因为这种编码太浪费空间了,又因为一些设备厂商已经对 2 字节编码技术投入大量成本,所以在 1996 年 7 月发布的 Unicode 2.0 中提出了 UTF-16 来打破 UCS-2 与 UCS-4 之间的僵局,UTF-16 在 2000 年被 IEFE 组织制定为RFC 2781标准。更多可参考:
由此可见,UCS-* 编码是一历史产物,目前来说,统一编码方案最终的赢家是 UTF-* 编码。
实战
操作系统
根据UTF-16 FOR PROCESSING,现在流行的三大操作系统 Windows、Mac、Linux 均采用 UTF-16 编码方案,上面链接也指出,现代编程语言像 Java、ECMAScript、.Net 平台上所有语言等在内部也都使用 UTF-16 来表示字符。
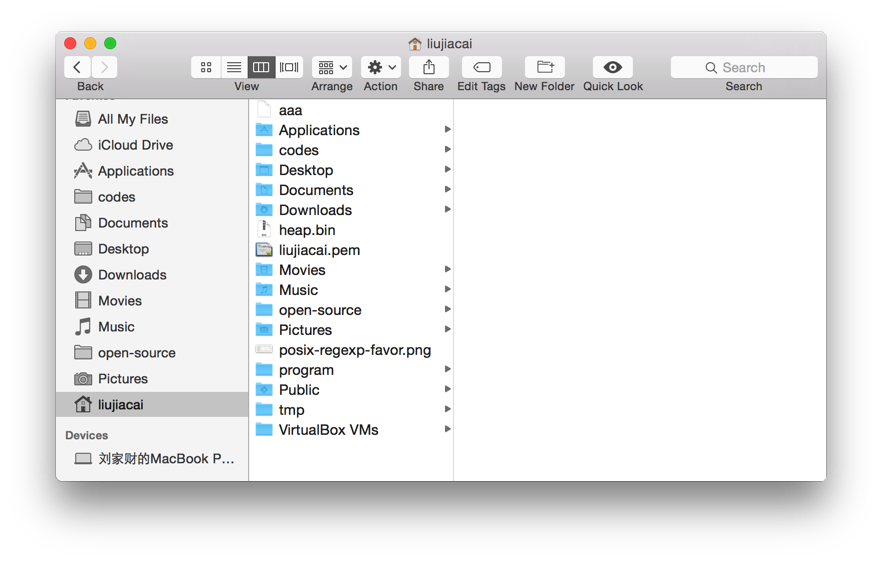 上图为 Mac 系统中文件浏览器 Finder 的界面,其中所有的字符,在内存中都是以 UTF-16 的编码方式存储的。
上图为 Mac 系统中文件浏览器 Finder 的界面,其中所有的字符,在内存中都是以 UTF-16 的编码方式存储的。
你也许会问,为什么操作系统都这么偏爱 UTF-16,Stack Exchange 上面有一个精彩的回答,感兴趣的可以去了解
Locale
为了适应多语言环境,Linux/Mac 系统通过 locale 来设置系统的语言环境,下面是我在 Mac 终端输入locale得到的输出
LANG="en_US.UTF-8" <==主语言的环境
LC_COLLATE="en_US.UTF-8" <==字串的比较排序等
LC_CTYPE="en_US.UTF-8" <==语言符号及其分类
LC_MESSAGES="en_US.UTF-8" <==信息显示的内容,如功能表、错误信息等
LC_MONETARY="en_US.UTF-8" <==币值格式的显示等
LC_NUMERIC="en_US.UTF-8" <==数字系统的显示信息
LC_TIME="en_US.UTF-8" <==时间系统的显示资料
LC_ALL="en_US.UTF-8" <==语言环境的整体设定
locale 按照所涉及到的文化传统的各个方面分成12个大类,上面的输出只显示了其中的 6 类。为了设置方便,我们可以通过设置LC_ALL、LANG来改变这 12 个分类熟悉。其优先级关系为
LC_ALL>LC_*>LANG
设置好 locale,操作系统在进行文本字节流解析时,如果没有明确制定其编码,就用 locale 设定的编码方案,当然现在的操作系统都比较聪明,在用默认编码方案解码不成功时,会尝试其他编码,现在比较成熟的编码测探技术有Mozila 的 UniversalCharsetDetection 与 ICU 的 Character Set Detection 。
编程语言
Java
一般来说,高级编程语言都提供都对字符的支持,像 Java 中的 Character 类就采用 UTF-16 编码方案。
这里有个文字游戏,一般我们说“某某字符串是XX编码”,其实这是不合理的,因为字符串压根就没有编码这一说法,只有字符才有,字符串只是字符的一串序列而已。 不过我们平时并没有这么严谨,不过你要明白,当我们说“某某字符串是XX编码”时,知道这其实指的是该字符串中字符的编码就可以了。 这也就回答了本文一开始提到问题,什么是字符串,这里用《Diving into Python 3》书上的一句话来总结这个问题:
Bytes are not character, bytes are bytes. Characters are an abstraction. A string is a sequence of those abstraction.
我们可以做个简单的实验来验证 Java 中确实使用 UTF-16 编码来存储字符:
public class EncodingTest {
public static void main(String[] args) {
String s = "中国人a";
try {
//线程睡眠,不要让线程退出
Thread.sleep(10000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在使用 javac 编译这个类时,javac 会按照操作系统默认的编码去解析字节流,如果你保存的源文件编码与操作系统默认不一致,是可能出错的,可以在启动 javac 命令时,附加-encoding <encoding>选项来指明源代码文件所使用的编码。
# 编译生成 .class 文件
javac -encoding utf-8 EncodingTest.java
# 执行该类
java EncodingTest
# 使用 jps 查看其 pid,然后用 jmap 把程序运行时内存的内容 dump 下来
jmap -dump:live,format=b,file=encoding_test.bin <pid>
# 在 Linux/Mac 系统上,使用 xxd 命令以十六进制查看该文件,我这里用管道传给了 vim
xxd encoding_test.bin | vim -
在 vim 中可以看到下图所示片段
 其中我用红框标注部分就是上面 EncodingTest 类中字符串
其中我用红框标注部分就是上面 EncodingTest 类中字符串s的内容,4e2d是“中”的 code point,56fd是“国”的 code point, 4eba是“人”的 code point,0061是“a”的 code point。而在 UTF-16 编码中,0-66535之间的字符直接用两个字节存储,这也就证明了 Java 中的 Character 是使用 UTF-16 编码的。
关于 Java 支持的所有编码,可以在 Oracle 官方文档 Supported Encodings中找到。
Python
Python 解释器
首先说下 Python 解释器如何读取、解析 Python 源程序。
在 Python 2 中,Python 解析器默认用 ASCII 编码(而非系统默认编码)来读取源程序,当程序中包含非 ASCII 字符时,解释器会报错,下面实验在我 Mac 上用 python 2.7.6 进行:
$ cat str.py
#!/usr/bin/env python
a = "中国人"
$ python str.py
File "str.py", line 2
SyntaxError: Non-ASCII character '\xe4' in file str.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
我们可以通过在源程序起始处用coding: name或coding=name来声明源程序所用的编码。
Python 3 中改变了这一行为,解析器默认采用 UTF-8 解析源程序。
字符类型
下面介绍 Python 2/3 中对字符的处理。
Python 2 中对字符的处理坑比较多,我这里单独写了篇文章介绍,感兴趣的可以参考:《Python2 中的编码问题》。
Python 3 中改变了这一行为,字符字面量直接表示为 Unicode 字符,引入以“字节”类型表示 Python 2 中的 str 类型,根据PEP-0393,Python 3 内部采用多种编码方案,而不仅仅是单单一种(细节可以参考c-api/unicode),这么做是权衡字符存储空间与字符操作速度后的结果,下面给出 CPython 中相关的定义:
typedef struct {
PyObject_HEAD
Py_ssize_t length;
Py_hash_t hash;
struct {
unsigned int interned:2;
unsigned int kind:2;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
} state;
wchar_t *wstr;
} PyASCIIObject;
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length;
char *utf8;
Py_ssize_t wstr_length;
} PyCompactUnicodeObject;
typedef struct {
PyCompactUnicodeObject _base;
// 可以看到,这里用了 union 类型,实际中 data 的类型为四种中的一个
// 同时,这里的 ucs2 相当于 utf-16;ucs4 相当于 utf-32
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data;
} PyUnicodeObject;
我们也可以做个实验验证 Python 中 Unicode 的存储方案:
$ python3
Python 3.5.0 (v3.5.0:374f501f4567, Sep 12 2015, 11:00:19)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> a = "中国人"
>>> import ctypes
>>> import binascii
>>> binascii.hexlify(ctypes.string_at(id(a), a.__sizeof__()))
b'010000000000000020c52200010000000300000000000000cfb73264f62ba107a81c22000100000000000000000000000000000000000000000000000
000000000000000000000002d4efd56ba4e0000'
>>> binascii.hexlify(a.encode('utf-16'))
b'fffe2d4efd56ba4e'
fffe是 UTF-16 的 BOM,表明我的Mac是小端模式。随后的2d4e表示中;fd56表示国;ba4e表示人,最后的0000表明 Python 中的字符串和 C 语言中的一样,用\0标明字符的结尾。
如果你比较细心,可能会发现 CPython 中字符相关的结构体中包含了length这一字段了,为什么这里又多此一举,加个尾标呢?其实这主要是为了Python 与 C 的交互,有了\0,Python 就可以直接读取 C 中的字符,也可以直接将 Python 中的字符直接传给 C 了。
参考:
JavaScript
JavaScript 遵循 ECMAScript 规范,在 ECMAScript 5.1 中有下面的定义:
A conforming implementation of this International standard shall interpret characters in conformance with the Unicode Standard, Version 3.0 or later and ISO/IEC 10646-1 with either UCS-2 or UTF-16 as the adopted encoding form, implementation level 3. If the adopted ISO/IEC 10646-1 subset is not otherwise specified, it is presumed to be the BMP subset, collection 300. If the adopted encoding form is not otherwise specified, it is presumed to be the UTF-16 encoding form.
也就是说 JavaScript 解释器的实现,即可以用 UCS-2 也可以用 UTF-16,但是考虑到 UTF-16 是 UCS-2 的超集,所以现在浏览器中的 JavaScript 引擎都用 UTF-16 存储字符串。 我这里做了个实验验证 Nodejs 中字符的存储方案:
# 1. 安装这个模块
npm install heapdump
# 2. 写个简单的程序
var heapdump = require('heapdump');
var a = "中国人";
heapdump.writeSnapshot('str_test.heapsnapshot');
# 3. 执行上面的程序后,找个二进制编辑器,打开生成的内存快照文件。我这里用了 xxd
xxd str_test.heapsnapshot | vim -

上图中的\u4E2D即为“中”,在内存中的字节序为5c75 3445 3244,这一串数字是\u4E2D的 ASCII 码。
参考:
HTML/XML
在我们的 Web 浏览器接收到来自世界各地的 HTML/XML 时,也需要正确的编码方案才能够正常显示网页,在现代的 HTML5 页面,一般通过下面的代码指定
<meta charset="UTF-8">
4.0.1 之前的 HTML 页面使用下面的代码
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
XML 使用属性标注其编码
<?xml version="1.0" encoding="UTF-8" ?>
仔细想想,这里有个矛盾的地方,因为我们需要事先知道某字节流的编码才能正确解析该字节流,而这个字节流的编码是保存在这段字节流中的,和“鸡生蛋,蛋生鸡”的问题有点像,其实这并不是一个问题,因为大部分的编码都是兼容 ASCII 编码的,而这些 HTML/XML 开始处基本都是 ASCII 字符,所以采用浏览器默认的编码方案即可解析出该字节流所声明的编码,在解析出该字节流所用编码后,使用该编码重新解析该字节流。
VIM
总结
这篇文章第一次写用了周末 2 天时间才完成,在后面陆陆续续又增删了不少,我只能说真是长见识了。在 wiki 上搜索的资料时,需要消耗较大精力去整理,因为各个编码都不是孤立存在的,要想完整了解某编码,需要从起发展历史开始,在不同编码条目间来回切换,才能对其有深入理解。这是我意料之外的。
字符串,这个既熟悉又陌生的东西,相信大家在看本文后,大家都能够对其有一全新的认识。
参考
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
- Are data type declarators like “int” and “char” stored in RAM when a C program executes?
- UTF-8 Everywhere
- 字符编码笔记:ASCII,Unicode和UTF-8
- Java: a rough guide to character encoding
- Python Unicode HOWTO
- How does my computer store things in memory?
- 谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
- The Python Language Reference: Data model