Clojure is a compiled language, yet remains completely dynamic – every feature supported by Clojure is supported at runtime.
Rich Hickey https://clojure.org/
这里的 runtime 指的是 JVM,JVM 之初是为运行 Java 语言而设计,而现在已经发展成一重量级平台,除了 Clojure 之外,很多动态语言也都选择基于 JVM 去实现。 为了更加具体描述 Clojure 运行原理,会分两篇文章来介绍。 本文为第一篇,涉及到的主要内容有:编译器工作流程、Lisp 的宏机制。 第二篇将主要讨论 Clojure 编译成的 bytecode 如何实现动态运行时以及为什么 Clojure 程序启动慢,这会涉及到 JVM 的类加载机制。
编译型 VS. 解释型
SO 上有个问题 Is Clojure compiled or interpreted,根据本文开始部分的官网引用,说明 Clojure 是门编译型语言,就像 Java、Scala。但是 Clojure 与 Java 不一样的地方在于,Clojure 可以在运行时进行编译然后加载,而 Java 明确区分编译期与运行期。
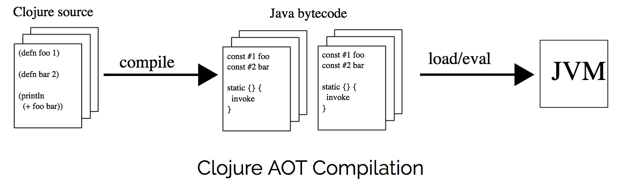

编译器工作流程
与解释型语言里的解释器类似,编译型语言通过编译器(Compiler)来将源程序编译为字节码。一般来说,编译器包括两个部分:
Clojure 的编译器也遵循这个模式,大致可以分为以下两个模块:
- 读取 Clojure 源程序 –> 分词 –> 构造 S-表达式,由 LispReader.java 类实现
- 宏扩展 –> 语义分析 –> 生成 JVM 字节码,由 Compiler.java 类实现

上图给出了不同阶段的输入输出,具体实现下面一一讲解。
LispReader.java
一般来说,具有复杂语法的编程语言会把词法分析与语法分析分开实现为 Lexer 与 Parser,但在 Lisp 家族中,源程序的语法就已经是 AST 了,所以会把 Lexer 与 Parser 合并为一个过程 Reader,核心代码实现如下:
for (; ; ) {
if (pendingForms instanceof List && !((List) pendingForms).isEmpty())
return ((List) pendingForms).remove(0);
int ch = read1(r);
while (isWhitespace(ch))
ch = read1(r);
if (ch == -1) {
if (eofIsError)
throw Util.runtimeException("EOF while reading");
return eofValue;
}
if (returnOn != null && (returnOn.charValue() == ch)) {
return returnOnValue;
}
if (Character.isDigit(ch)) {
Object n = readNumber(r, (char) ch);
return n;
}
IFn macroFn = getMacro(ch);
if (macroFn != null) {
Object ret = macroFn.invoke(r, (char) ch, opts, pendingForms);
//no op macros return the reader
if (ret == r)
continue;
return ret;
}
if (ch == '+' || ch == '-') {
int ch2 = read1(r);
if (Character.isDigit(ch2)) {
unread(r, ch2);
Object n = readNumber(r, (char) ch);
return n;
}
unread(r, ch2);
}
String token = readToken(r, (char) ch);
return interpretToken(token);
}
Reader 的行为是由内置构造器(目前有数字、字符、Symbol 这三类)与一个称为read table的扩展机制(getMacro)驱动的,read table 里面每项记录提供了由特性符号(称为macro characters)到特定读取行为(称为reader macros)的映射。
与 Common Lisp 不同,普通用户无法扩展 Clojure 里面的read table。关于扩展read table的好处,可以参考 StackOverflow 上的 What advantage does common lisp reader macros have that Clojure does not have?。Rich Hickey 在一 Google Group里面有阐述不开放 read table 的理由,这里摘抄如下:
I am unconvinced that reader macros are needed in Clojure at this time. They greatly reduce the readability of code that uses them (by people who otherwise know Clojure), encourage incompatible custom mini- languages and dialects (vs namespace-partitioned macros), and complicate loading and evaluation. To the extent I’m willing to accommodate common needs different from my own (e.g. regexes), I think many things that would otherwise have forced people to reader macros may end up in Clojure, where everyone can benefit from a common approach. Clojure is arguably a very simple language, and in that simplicity lies a different kind of power. I’m going to pass on pursuing this for now,
截止到 Clojure 1.8 版本,共有如下九个macro characters:
Quote (')
Character (\)
Comment (;)
Deref (@)
Metadata (^)
Dispatch (#)
Syntax-quote (`)
Unquote (~)
Unquote-splicing (~@)
它们的具体含义可参考官方文档 reader#macrochars。
Compiler.java
Compiler 类主要有三个入口函数:
- compile,当调用
clojure.core/compile时使用 - load,当调用
clojure.core/require、clojure.core/use时使用 - eval,当调用
clojure.core/eval时使用

这三个入口函数都会依次调用 macroexpand、analyze 方法,生成Expr对象,compile 函数还会额外调用 emit 方法生成 bytecode。
macroexpand
Macro 毫无疑问是 Lisp 中的屠龙刀,可以在编译时自动生成代码:
static Object macroexpand(Object form) {
Object exf = macroexpand1(form);
if (exf != form)
return macroexpand(exf);
return form;
}
macroexpand1 函数进行主要的扩展工作,它会调用isMacro判断当前Var是否为一个宏,而这又是通过检查var是否为一个函数,并且元信息中macro是否为true。
Clojure 里面通过defmacro函数创建宏,它会调用var的setMacro函数来设置元信息macro为true。
analyze
interface Expr {
Object eval();
void emit(C context, ObjExpr objx, GeneratorAdapter gen);
boolean hasJavaClass();
Class getJavaClass();
}
private static Expr analyze(C context, Object form, String name)
analyze 进行主要的语义分析,form参数即是宏展开后的各种数据结构(String/ISeq/IPersistentList 等),返回值类型为Expr,可以猜测出,Expr的子类是程序的主体,遵循模块化的编程风格,每个子类都知道如何对其自身求值(eval)或输出 bytecode(emit)。

emit
这里需要明确一点的是,Clojure 编译器并没有把 Clojure 代码转为相应的 Java 代码,而是借助 bytecode 操作库 ASM 直接生成可运行在 JVM 上的 bytecode。
根据 JVM bytecode 的规范,每个.class文件都必须由类组成,而 Clojure 作为一个函数式语言,主体是函数,通过 namespace 来封装、隔离函数,你可能会想当然的认为每个 namespace 对应一个类,namespace 里面的每个函数对应类里面的方法,而实际上并不是这样的,根据 Clojure 官方文档,对应关系是这样的:
- 函数生成一个类
- 每个文件(相当于一个命名空间)生成一个
<filename>__init的加载类 gen-class生成固定名字的类,方便与 Java 交互
生成的 bytecode 会在本系列第二篇文章中详细介绍,敬请期待。
eval
每个 Expr 的子类都有 eval 方法的相应实现。下面的代码片段为 LispExpr.eval 的实现,其余子类实现也类似,这里不在赘述。
public Object eval() {
IPersistentVector ret = PersistentVector.EMPTY;
for (int i = 0; i < args.count(); i++)
// 这里递归的求列表中每项的值
ret = (IPersistentVector) ret.cons(((Expr) args.nth(i)).eval());
return ret.seq();
}
总结
之前看 SICP 后实现过几个解释器,但是相对来说都比较简单,通过分析 Clojure 编译器的实现,加深了对 eval-apply 循环的理解,还有一点就是揭开了宏的真实面貌,之前一直认为宏是个很神奇的东西,其实它只不过是编译时运行的函数而已,输入与输出的内容既是构成程序的数据结构,同时也是程序内在的 AST。