GC 算法作为计算机科学领域非常热的研究话题之一,最早可追溯到 1959 年1,由 John McCarthy 在 Lisp 中实现来简化内存管理。早期的 Lisp 之所以被大众诟病慢,主要原因就是当时的 GC 实现相对简单,对程序的影响(overhead)比较严重。经过几十年的发展,GC 算法已经很成熟了,可以完全摆脱「速度慢」这个让人望而却步的标签。
单就 JVM 这个平台来说,GC 算法一直在优化、演变,从最初的串行到高吞吐量的并行,为了解决高延迟又演化出了 CMS(Concurrent Mark Sweep),为了解决碎片问题,又开发了 G1,Oracle 内部还在不断尝试新算法,比如 ZGC。
对于这么一个庞大但有趣的话题,我决定写一系列文章来介绍,首先会介绍 GC 的必要性、常见回收策略,这些是语言无关的;然后会重点介绍 JVM 上的 GC 实现;再之后会对现较为流行的脚本语言(js/python/ruby)所用的 GC 算法做一些探索。每个语言在实现 GC 算法时都有其独特之处,所以最后希望能深入到源代码级别,做到真正的深入浅出(inside out)。我所参考的资料主要来自 wikipedia 以及一些前辈的总结(Google 检索),当然对于能实践的部分我会给上相关测试代码。
所以如果读者发现文中有错误,麻烦指出,我会及时更新,保证不对后面学习者产生误导。好了,进入正题。
为什么需要 GC
在计算机诞生初期,在程序运行过程中没有栈帧(stack frame)需要去维护,所以内存采取的是静态分配策略,这虽然比动态分配要快,但是其一明显的缺点是程序所需的数据结构大小必须在编译期确定,而且不具备运行时分配的能力,这在现在来看是不可思议的。在 1958 年,Algol-58 语言首次提出了块结构(block-structured),块结构语言通过在内存中申请栈帧来实现按需分配的动态策略。在过程被调用时,帧(frame)会被压到栈的最上面,调用结束时弹出。栈分配策略赋予程序员极大的自由度,局部变量在不同的调用过程中具有不同的值,这为递归提供了基础。但是后进先出(Last-In-First-Out, LIFO)的栈限制了栈帧的生命周期不能超过其调用者,而且由于每个栈帧是固定大小,所以一个过程的返回值也必须在编译期确定。所以诞生了新的内存管理策略——堆(heap)管理。
堆分配运行程序员按任意顺序分配/释放程序所需的数据结构——动态分配的数据结构可以脱离其调用者生命周期的限制,这种便利性带来的问题是垃圾对象的回收管理。C/C++/Pascal 把这个任务交给了程序员,但事实证明这非常容易出错,野指针(wild pointer)、悬挂指针(dangling pointer)是比较典型的错误。在另一些场景中,动态分配的对象传入了其他过程中,这时程序员或编译器就无法预测这个对象什么时刻不再需要,现如今的面向对象语言,这种场景更是频繁,这也就间接促进了自动内存管理技术的发展。而且即便是 C/C++ ,也有类似 Boehm GC 这样的第三方库来实现内存的自动管理。可以毫不夸张的说,GC 已经是现代语言的标配了。
图灵机模型

我们选择 GC 而不是手动释放资源的原因很简单:靠人来约束很容易出问题。当然对于实时性较高(炒股)、资源相对紧张(比如嵌入式设备)的程序,手工释放资源还是首选。
GC 的定义
上面一小节介绍了 GC 的对象是内存,但内存在一运行的程序中通常会划分为多个区域,其中最常见的是栈(stack) 与堆(heap)。栈的空间一般较小,在一个函数调用时用以分配其内部变量,在函数调用结束时自动回收,这里并不涉及到 GC;而堆的空间一般较大,可以在多个函数间共享数据,程序可根据需要进行动态申请,GC 主要是工作在这个区域。所以我们可以这么定义 GC:
GC 是一种自动管理内存的技术,用来回收(释放) heap 中不再使用的对象。
GC 过程中涉及到两个阶段:
- 区分活对象(live object)与垃圾对象(garbage)
- 回收垃圾对象的内存,使得程序可以重复使用这些内存
GC 常用策略
追踪(Tracing)
这是目前使用范围最广的技术,一般我们提到 GC 都是指这类,实现这种机制的系统有:JVM/.NET/OCaml。 这类 GC 从某些被称为 root 的对象开始,不断追踪可以被引用到的对象,这些对象被称为可到达的(reachable),其他剩余的对象就被称为 garbage,并且会被释放。
对象的可到达行
一般来说,可到达的对象主要包含下面两类情况:
- root 对象,这包括全局对象、调用栈(call stack)上的对象(包括内部变量与参数)
- 从 root 对象开始,间接引用的对象
采用可到达行来区分一个对象是否为 garbage 有一定的局限性,因为程序中真正使用一个对象时距其创建可能需要很久。比如:
1Object x = new Foo();
2Object y = new Bar();
3x = new Quux();
4/* 这这里,x 之前为赋值的 Foo 对象以及不可到达,可以被 GC 回收
5 * 这种情况称为: syntactic garbage
6 */
7
8if(x.check_something()) {
9 x.do_something(y);
10}
11System.exit(0);
12/* 在这里,y 是否能回收取决于 if 条件里面的函数执行结果,而这个函数可能会发生死循环或者返回false
13 * 这种情况被称为: semantic garbage
14 */
要确定 semantic garbage 是否能被回收,需要去分析代码,这和停机问题类似,没有固定的算法;而对于 syntactic garbage,只需要分析引用链就可以了。
强引用与弱引用
追踪类 GC 使用引用来决定一个对象的可到达性,但是在程序中有时会希望能以弱引用的方式指向一个对象,弱引用不会保护该对象被 GC 回收。如果该对象被回收了,那么这个弱引用会被赋予一个安全值(一般为NULL)。使用弱引用可以解决很多问题,比如:
- 循环引用
- 在 Map 中,如果允许 key 为弱引用,那么 GC 就可以回收用不到对象,而不会因为 Map 中的引用让其一直留在内存中,适用于做缓存
在一些实现中,弱引用被分成了几个类别。比如在 JVM 中,提供了三类,soft、phantom、常规的弱引用,其区别可参考我之前的文章Java WeakHashMap 源码解析。
基本算法 mark-and-sweep
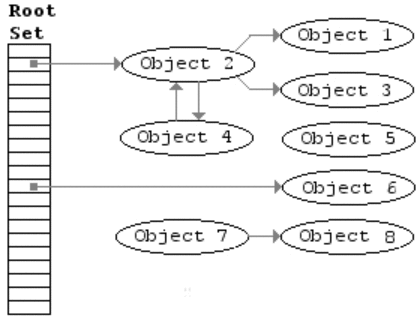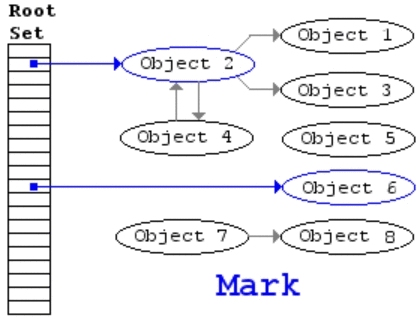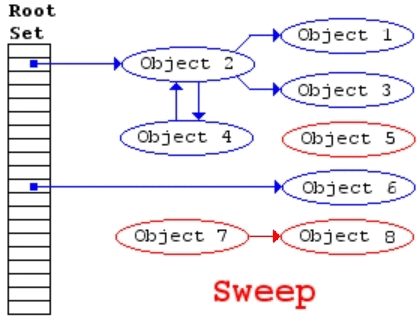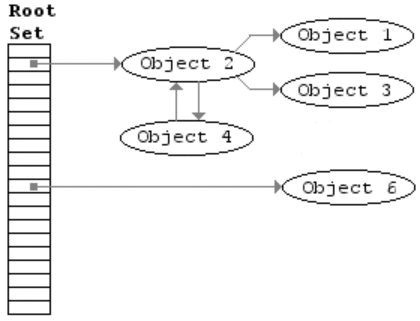
该算法主要包括两步,
- mark,从 root 开始进行树遍历,每个访问的对象标注为「使用中」
- sweep,扫描整个内存区域,对于标注为「使用中」的对象去掉该标志,对于没有该标注的对象直接回收掉
该算法的缺点有:
- 在进行 GC 期间,整个系统会被挂起(暂停,Stop-the-world),所以在一些实现中,会采用各种措施来减少这个暂停时间
- heap 容易出现碎片。实现中一般会进行 move 或 compact。(需要说明一点,所有 heap 回收机制都会这个问题)
- 在 GC 工作一段时间后,heap 中连续地址上存在 age 不同的对象,这非常不利于引用的本地化(locality of reference)
- 回收时间与 heap 大小成正比
原始版的 mark-sweep 问题虽然比较多,但是有一系列的优化措施来解决(mark-compact/copying/non-copying..),后面会涉及到。
引用计数(Reference counting)

引用计数类 GC 会记录每个对象的引用次数,当引用次数为0时,就会被回收,这类 GC 实现起来较为简单。采用这类 GC 的主流语言有:Python/PHP/Perl/TCL/Objective-C。 与追踪类 GC 相比,有以下两处优势:
- 可以保证对象引用为0时立马得到清理,无不确定行
- 大多数操作具有增量特性(incremental),GC 可与应用交替运行,不需要暂停应用即可完成回收功能
- 可以用来优化运行时性能。比如函数式编程中所推崇的「不可变数据结构」的更新就能收益:运行时知道某个对象的引用为1,这时对这个对象进行修改,类似
str <- str+"a",那么这个修改就可以在本地进行,而不必进行额外的 copy
除了上面介绍的优势,引用计数具有以下几处劣势:
- 无法解决循环引用。CPython 使用独特的环检测算法规避3,后面文章再分析该算法;此外也可以用弱引用的方式解决
- 实现一个高效率的引用计数 GC 比较困难。主要包括下面两方面
- space overhead,每个对象需要额外的空间来存储其引用次数,在追踪类 GC 中,用以标注对象是否在使用中的flag 位一般放在引用变量里面
- speed overhead,在增加/减少对象的引用时,需要修改引用次数。这对于栈上的赋值(on-stack assignment,比如函数调用是的参数、函数内部变量等)影响是非常大的,因为之前只需要简单修改寄存器里面的值,现在需要一个原子操作(这涉及到加锁,会浪费几百个 CPU cycles)4
- 减少一个对象的引用计数时,会级联减少其引用对象的计数,这就可能造成同时删除过多的对象。在实现中一般会把要回收的对象放入一队列,当程序申请大小为 N 的内存时,从这个队列取出总体积不小于 N 的一个或多个对象将其回收。
由于以上缺陷,对性能要求较高的系统在实现 GC 时一般不会选择引用计数,而会转向追踪类(追踪类 GC 虽然有 stop-the-world 的问题,但是可以通过各种措施优化,后面会介绍到)。 但由于引用计数实现较为简单,除了用在 GC 领域,还广泛用在管理系统资源上。比如:大多数文件系统会维持特定文件/block的引用数(inode里面的link count),这些引用被称为 hard links。当引用数为0时,这个文件就可以被安全的删除了。
逃逸分析(Escape_analysis)
这里主要是指通过逃逸分析,来将在 heap 中分配的对象分配到 stack 中。如果一个对象的使用只出现在某一函数内(即没有 escape),那么这个对象就完全可以分配在该函数的 stack 中,减少 GC 的工作量。
JVM 中有相关实现,后面文章也会涉及到,感兴趣的朋友可以先参考:
总结
「追踪」与「引用计数」这两类 GC 各有千秋,真正的工业级实现一般是这两者的结合,不同的语言有所偏重而已。可以参考下面几处提问:
- Why doesn’t Apple Swift adopt the memory management method of garbage collection like Java uses?
- How does garbage collection compare to reference counting?
- Why doesn’t Java use reference counting based GC?
总体来说,追踪类 GC 是效率最高的算法5,其变种也比较多,后面的文章也会重点讲述此类 GC,这里面有趣的内容非常多,比如:semispace(用以提高 sweep 的速度与减少内存碎片)、Cheney’s algorithm / Baker’s Algorithm(这两算法都是对 semispace 的优化)、generational GC(减少 GC 作用范围)、incremental/concurrent GC(减少 stop-the-world 时间)。 Stay Tuned!