上文介绍的增量式 GC 是对 mark 阶段的一大优化,可以极大避免 STW 的影响。本文将要介绍的分代式 GC 根据对象生命周期(后面称为 age)的特点来优化 GC,降低其性能消耗。
阅读本文需要熟悉之前提及的术语。
分代的必要性
虽然对象的生命周期因应用而异,但对于大多数应用来说,80% 的对象在创建不久即会成为垃圾1。因此,针对不同 age 的对象「划分不同区域,采用不同的回收策略」也就不难理解了。
对于 Copying GC 来说,需要在两个 semispace 间移动对象,如果移动对象较大,就会对程序造成较大影响,而分代就能解决这个问题。简单情况下可以分为两个代:younger、older。
younger 用于分配新对象,在这里的对象经过几轮 GC 后会移动到 older。younger 与 older 相比空间要小,且 GC 发生更频繁。

分代的问题
天下没有免费的午餐,GC 采用分代算法,一个首要的问题是「如何在不回收 older 的同时安全的回收 younger 里面的对象」。由于引用关系图是全局的属性,older 里面的对象也必须考虑的。比如 younger 里面的一对象只被 older 里面的对象引用了,如何保证 GC 不会错误的回收这个对象呢?
避免上述问题的一个方法是采用写屏障(write barrier),在 mutator 进行指针存储时,进行一些额外的操作(bookkeeping)。写屏障的主要目的是保证所有由 older-->younger 的指针在进行 younger 内的 GC 时被考虑在内,并且作为 root set 进行 copy 遍历。需要注意的是,这里的写屏障与增量式 GC 同样具有一定的保守性。这是由于所有由 older-->younger 的指针都会被当作 root set,但在 older 内对象的 liveness 在进行下一次 older GC 前是不可知的,这也就造成了一些 floating garbage,不过这在实现中问题不是很大。
为了独立回收 older,通过记录所有由 younger-->older 的指针也是可行的,不过这会比较消耗性能。这是因为:
在大多数情况下,由
younger-->older的指针数目要远大于older-->younger的,这是符合程序运行规律的——创建一个新对象,将至指向一个老对象。
即便不记录 younger-->older 的指针,也可以在不回收 younger 的前提下回收 older,只不过这时会把 younger 里面的所有对象作为 root set。尽管这样遍历的时间会与 younger 里面的对象数目成正比,但考虑到 younger 内对象数量一般都要小于 older 的,而且遍历操作的消耗要远小于 copying,所以这也是一种可以接受的方式。
除了上面交叉引用的问题,对于一个分代的 GC 来说,还需要考虑下面几个方面:
- 提升策略(advancement policy)。在一个代内的对象经过多少次 GC 会晋级到下一个代
- 堆组织(heap organization)。在代与代之间或者一个代内,heap 空间如何组织可以保证高的 locality 与 缓存命中率
- 代之间的交叉引用(intergenerational references)。采用哪种方式来记录这些指针最好?dirty bit or indirect table
下面就针对这三点分别进行阐述。
提升策略
最简单的提升策略是在每次 GC 遍历时,把 live 的对象移动到下一代去。这样的优势有:
- 实现简单,不需要去区分一个代内不同对象的 age。对于 copying GC 来说,只需要用一块连续的区域表示即可,不需要 semispace,也不需要额外的 header 来保存 age 信息
- 可以尽快的把大对象提升的 GC 频率小的下一代中去
当然,这样做的问题也比较明显,可能会把一些 age 较小的对象移动到下一代中去,导致下一代被更快的填满,所以一般会让 younger 里面的对象停留一次,即第二次 GC 时才去提升,当然这时就需要记录对象的 age 了。
至于是不是需要停留两次,这个就不好说了,这个和应用也比较相关。一般来说,如果代分的少,比如2个,那么会倾向多停留几次,减慢 older 被填满的速度;如果代的数目大于2,那么就倾向于快速提升,因为这些对象很有可能在中间的某个代就会死亡,不会到达最终的 older。
堆组织
分代式 GC 需要对不同 age 的对象采取不同的处理方式,所以在 GC 遍历时,必须能够判断当前对象属于哪个代,写屏障也需要这个信息来识别 older-->younger 指针。
- 对于 copying GC 来说,一般是把不同 age 的对象放在不同的连续区域内,这样一个对象的代就能够从内存地址推断出来了。也有一些系统不采用连续地址,而是采用由
page number of object-->generation的表来辅助判断。 - 对于 non-copying GC,一般是存放在 header 内
Subareas in Copying
分代式 copying GC 一般会把 generation 分为几个子区域,比如 semispace,通过来回的移动对象让它们一直处于当前代中。如果一个代内只有一个区域,那么每次 GC 时都需要把对象提升到下一代(没有可移动的地方)。 但是 semispace 的 locality 比较差,一个代的内存只有一半可以使用,且来回需要移动。
Ungar’s Generation Scavenging
Ungar 在其论文《Generation Scavenging》 中提出一个解决方法:
一个代内除了两个 semispace 外,还有第三个区域,这里称为Third。在 Third 内分配新对象,在 GC 时,Third 内 live 对象与 semispace 中的一个对象会复制到 semispace 中的另一个去,GC 结束时 Third 会被清空,用于再次分配对象。这样就能够与只有一个区域的代类似的 locality 了。
乍一看,增加的 Third 区域会增加内存使用,但实际情况要好很多。Third 区域会被充分利用,semispace 用来保存每次 GC 后的存活对象(survivors)。一般来说,新创建的对象只有少部分能“活过”一次 GC,所以每个 semispace 中只有一小部分会使用,因此总的来说内存使用较小。
最后一个代(oldest generation,后面称为 oldest)在一些系统中有特殊处理。比如,在 Lisp Machine 中,每次 GC 后,大多数代都会被清空,并将其内对象拷贝到下一代去,但是 oldest 后面没有可用代了,因此 oldest 内会被分为 semispace。另一个优化是分配一个特殊的区域,称为 static space,用来分配 system data & compiled code 等这些基本不会变的数据,这个区域基本不会有 GC。
在一些基于 Ungar 的 Generation Scavenging 的系统中,把 oldest 分为一个区域,在这个区域使用 mark-compact 算法。使用一个区域可以提高内存利用率,MC 虽然比 copying 算法成本更高,但对于 oldest 来说减少换页(page fault)也是有价值的。(copying GC 由于 semispace 的原因,所以内存使用率只有一半,所以更容易导致发生换页的问题2)。关于虚拟内存的分页对 GC 影响的研究不是很多,感兴趣可以参考下面的链接:
- Virtual Memory, Paging, and Swapping
- Are there any garbage collectors that take into account paging?
- Relation between garbage collection and swapping,paging
Generations in Non-copying
上面的讨论主要围绕 copying GC 来说,其实那些技巧也可以用在 non-copying GC 之上,只不过它们更容易发生碎片问题。在增量式 GC 那里使用三色标记来抽象,分代算法可以用不同 age 的对象集合来抽象。在 GC 遍历时,通过检查 header 里面的 age 来决定是否需要提升。
其他讨论
- 对于 copying GC 来说,大对象会被特殊的分配在一特殊区域「large object area」来避免拷贝。
- 对于明确指定不含有指针的对象,最好也能与其他对象分开,来降低检查交叉引用的成本。
- 一般情况下,对 younger 代采用 stop-and-copy 方式的 GC;对 older 采用 incremental-and-sweep GC
交叉引用
上面已经介绍的,older-->younger 的交叉引用是由写屏障来保障的。对于某些系统(如 Lisp,指针存储指令占全部指令的1%3),这个写屏障的成本对分代式 GC 来说非常严重,因此写屏障的策略就十分重要了。下面介绍几种常见的策略
Indirect tables
重定向表(indirect tables)的思路是这样的:
所有 older-->younger 的指针经由一个称为「entry table」的表进行中转,每个代都有其对应的 entry table 来记录后一个代指向当前代的指针。这样在回收一个代时,只需要把 entry table 里面的引用考虑在内就可以了。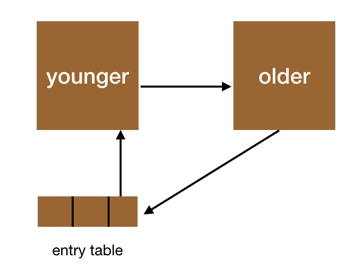
但这种重定向表在普通机器(stock hardware)上不够快或高效,因此最近的分代式 GC 都避免使用这种方式,而是采用记录的方式(pointer recording schemes)来保存这些交叉引用。
Ungar’s Remembered Sets
Ungar 的 generation scavenging 采用一个称为 Remembered Sets(后面简写 RS) 的结构来记录交叉引用。在每一次指针存储时,写屏障通过检查
- 将要保存的对象是否为指针
- 指针是否指向 younger
- 是否被保存到 older 内
这三个条件,判断是否会创建交叉引用,如果上述三个条件都满足,就会把 older 的对象添加到 RS 中。每个对象的 header 都有一位表示其是否存在于 RS 中,所以可以保证 RS 的内元素的唯一性,这样可以缩短扫描 RS 的时间。
这种方式的主要弊端是 RS 里面的所有对象在 GC 时,需要全部扫描一边,这对于下面两种情况来说成本是比较高的:
- younger 里面的一对象可能被多个 older 里的对象引用,这会导致不必要的重复检查
- RS 里面的对象在回收 older 时需要再被扫描一边,这里面有一些大对象时情况会更严重
Page Marking
Moon 在为 Symbolics Lisp machine 开发的 Ephemeral GC 中采用了另一种 pointer-recording 方式。这种方式不去记录哪些对象中含有交叉引用,而是记录哪些「虚拟内存页(virtual memory pages)」里保存了交叉引用。采用页为记录单位避免了扫描特大对象的问题。虽然整个页还需要扫描,但成本对 Symbolics 公司生产的机器来说不是很大,这是因为:
- 有特殊的 tag 支持,可以让检查代的操作非常快的完成
- page 相对来说比较小
但这种方式对于普通机器来说就要慢很多了,除了普通机器的 page 较大(一般4K)以及没有特殊的 tag 支持外,还需要能够「从头扫描任意页」,这也是比较困难的,Symbolics 机器是因为每个 machine word 都有一额外标志位,所有这个扫描才比较快。
Word Marking
Sobalvarro 通过为普通机器适配 Moon 的 Page marking 算法,采用 word marking 策略,使用一个 bitmap 来记录哪些 machine word 有交叉引用,这就避免了扫描任意页的问题。 但这种方式最大的问题时对于大 heap 来说,bitmap 会比较大,需要占整个内存空间的1/3,bitmap 如果是一维线性数组的话会比较耗时。
Card Marking
为了解决页太大、字太小的问题,Sobalvarro 又提出了一个中等大小的新单位,也就是 card。card 避免了
- page 太大,造成需要额外遍历多余对象
- word 大小,造成遍历 bitmap 过长

总结
分代式 GC 由于其普适性,已经被多数语言所采纳,比如:
- JavaScript:V8、SpiderMonkey
- Generational GC in Python and Ruby,这里面有介绍 Python 如何使用分代来解决「循环引用」
- Mono Generational GC
- JVM Generations
截止到这篇文章,GC 的理论知识就告一段落,主要参考了 Wilson 的论文 Uniprocessor Garbage Collection Techniques。有很多细节点都没有涉及到,比如
- locality 在不同策略下的影响
- 一个对象包含数据部分与指针部分,如何识别出指针
可能是 C 语言已经离我比较久远,需要重新拾起来才能更好理解不同 GC实现上的取舍,谁让现如今大多数编译器、运行时都是由 C/C++ 编写的呢? 不过我觉得最重要的一点就是意识到 GC 的技术是通过一代又一代大师的努力不断进化的,像 Cheney、Baker、Guy Steele。即便站在巨人肩膀上的我们,GC 这个话题也还有很多问题需要解决。 后面的文章会主要集中在 JVM 的 GC,包括原理、调优、实现细节,做到理论与实践相结合。