使用 Go 已经一年,深深沉浸在其简洁的设计中,就像其官网描述的:
Go is expressive, concise, clean, and efficient. It's a fast, statically typed, compiled language that feels like a dynamically typed, interpreted language.
Rob Pike 在 Simplicity is Complicated 中也提到 Go 的简洁是其流行的重要原因。简洁并不意味着简单,Go 有着诸多设计确保了把复杂性隐藏在背后。本文就结合笔者自身经验,来讨论 Go 中struct/interface 的设计理念与最佳实践,帮助读者写出健壮、高效的 Go 程序。
Struct
Go 的设计目标是取代 C/C++,所以 Go 里面的 struct 和 C 的类似,与 int/float 一样属于*值类型*,值类型的特点是内存紧凑,大小固定,对 GC 与内存访问来说都比较友好。
1type Point struct { X, Y int }
2type Rect1 struct { Min, Max Point }
3type Rect2 struct { Min, Max *Point }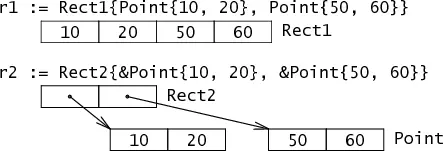
从上面图可以看到, Point Rect1 Rect2 在内存中都是连续的。值类型在使用时需要注意以下两点:
- 在进行赋值时,会对其值进行一次拷贝,这和 Java 中以引用为主的 Object
有所不同:
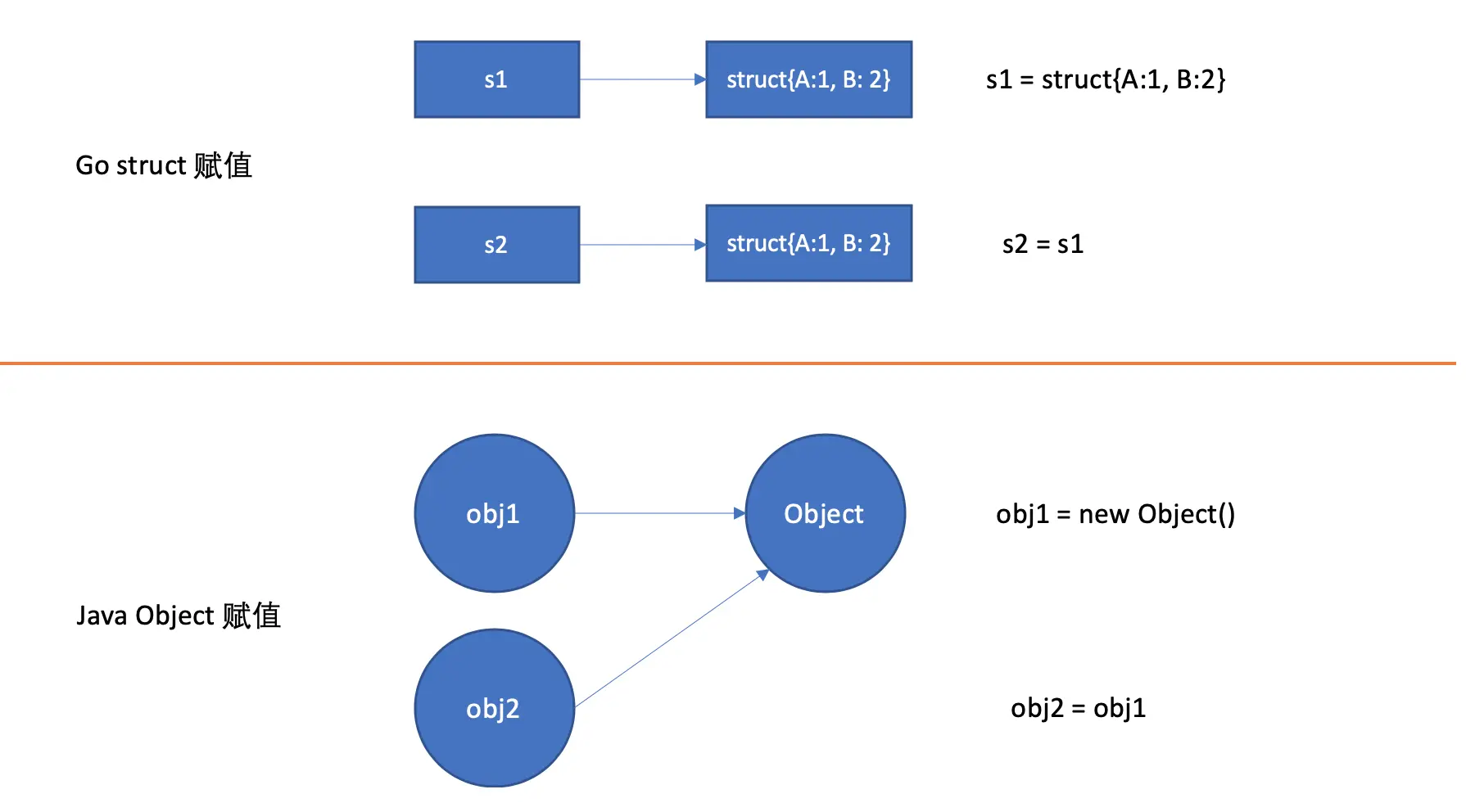
Go struct 与 Java Object 对比 - 因为值类型的赋值会进行拷贝,所以当需要改变其值时,需要将其定义为指针类型。
1 type student struct {
2 name string
3 }
4
5 foo := student{name: "foo"}
6 bar := foo
7 bar.name = "bar"
8 fmt.Println(foo.name) // 输出 foo
9
10 bar2 := &foo
11 bar2.name = "bar"
12 fmt.Println(foo.name) // 输出 bar上面的示例还比较简单,但是当把 struct 嵌套在其他结构中时,则容易忽视,比如在使用 for range 遍历 []struct=、=map[xx]struct 时。for range 使用时还会有些坑,可参考 Dig101 - Go 之 for-range 排坑指南,这里不再赘述。
而且,在某些场景下,Go 直接在语言层面限制对 struct 的修改。这里举一例子:
1 m := map[int]student{
2 1: {name: "1"},
3 }
4 m[1].name = "2" // 编译错误: cannot assign to struct field m[1].name in map可以看到,无法直接对 map 中的 struct 进行赋值,这是由于 m[1] 得到的是原有 struct 的拷贝,即使编译器允许这里的赋值,map 中的 struct 值也不会改变,所以编译器直接不允许这种情况。其次, 这里的赋值操作是个 read-modify-write 操作,很难其保证原子性,更多讨论可参考 #3117。解决方式有两种:
1// 1. 使用临时变量
2m := map[int]student{1: {name: "1"}}
3tmp := m[1]
4tmp.name = "2"
5m[1] = tmp
6
7// 2. 使用指针类型
8m := map[int]*student{1: {name: "1"}}
9m[1].name = "2"笔者多次遇到这个“坑”,那是不是说把所有的 struct 都定义为指针就好了呢?这里需要了解下 Go 的逃逸分析才能回答这个问题。
逃逸分析
逃逸分析的主要作用是决定对象分配在内存中的位置,Go 会尽量分配在 stack 上,这样的好处显而易见:回收简单,减轻 GC 压力。可以通过 go build -gcflags -m xx.go 查看
1func returnByValue(name string) student {
2 return student{name}
3}
4
5func returnByPointer(name string) *student {
6 return &student{name}
7}
8
9./snippet.go:6:18: &student literal escapes to heap可以看到 returnByPointer 方法的返回值会逃逸,最终分配在 heap 上,关于变量分配在 stack / heap 上的性能差距,可参考:bench_test.go。测试结果:
1go test -run ^NOTHING -bench Struct *.go
2goos: darwin
3goarch: amd64
4BenchmarkPointerVSStruct/return_pointer-8 33634951 34.3 ns/op 16 B/op 1 allocs/op
5BenchmarkPointerVSStruct/return__value-8 530202802 2.23 ns/op 0 B/op 0 allocs/op
6BenchmarkPointerVSStruct/value_receiver-8 433067940 2.77 ns/op 0 B/op 0 allocs/op
7BenchmarkPointerVSStruct/pointer_receiver-8 431380804 2.72 ns/op 0 B/op 0 allocs/op
8PASS
9ok command-line-arguments 5.889s可以看到:
- 方法返回 pointer 时,会有一次 heap 分配
- 方法返回 value 时,则没有 heap 分配,说明所有变量都分配在 stack 上
- 对于 receiver 为 pointer 或 value 性能差别不大,这是因为 s 在两种情况下均无逃逸,并且拷贝 struct 本身与拷贝指针(8 字节)的代价差不多
这个测试也说明变量分配在内存中的位置,与是否为指针无关。结合上面的测试结果,可以按照下述流程确定是否采用指针:
- 需要改变状态(比如包含 waitgroup/sync.Poll/sync.Mutex 等),选用指针
- 作为函数返回值
unsafe.Sizeof(struct)大于一定阈值时,拷贝的时间大于在 heap 上分配的时间,选用指针 - 作为函数参数、for range 对象时(均会对值进行拷贝) ,如果对象比较大,选用指针
- 除此之外,struct 即可
为了确定出 2 中的阈值,可以在 struct 中添加一数组(数组也是值类型),再来运行上述测试即可。在笔者机器中,这个阈值大概为 72K。
1type student struct {
2 name string
3 dummy [9000]int64 // 添加一数组元素
4}
5
6BenchmarkPointerVSStruct/return_pointer-8 150147 8147 ns/op 73728 B/op 1 allocs/op
7BenchmarkPointerVSStruct/return__value-8 138591 8146 ns/op 0 B/op 0 allocs/op很少有 struct 会达到这个量级,这是由于 Go 中常用的 slice/map/string 均为复合类型,复合类型的特点是大小固定,比如 string 类型只占 16 个字节(64 位系统而言),类似下面的结构
1type StringHeader struct {
2 Data uintptr
3 Len int
4}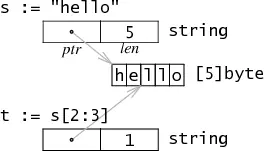
下图总结了 Go 中数据类型的分类:
| 值类型 | 复合类型 |
| bool | slice |
| numeric | map |
| (unsafe)pointer | channel |
| struct | function |
| array | interface |
| string |
1 fmt.Println(map[string]uint64{
2 "ptr": uint64(unsafe.Sizeof(&struct{}{})),
3 "map": uint64(unsafe.Sizeof(map[bool]bool{})),
4 "slice": uint64(unsafe.Sizeof([]struct{}{})),
5 "chan": uint64(unsafe.Sizeof(make(chan struct{}))),
6 "func": uint64(unsafe.Sizeof(func() {})),
7 "interface": uint64(unsafe.Sizeof(interface{}(0))),
8 })
9
10 // 输出
11 map[chan:8 func:8 interface:16 map:8 ptr:8 slice:24]可以看到,
- chan/func/map/ptr 均为 8 个字节,即一个指向具体数据的指针
- interface 为 16,两个指针,一个指向具体类型,一个指向具体数据。细节可参考 Russ Cox 的 Go Data Structures: Interfaces
- slice 为 24,包括一个指向底层 array 的指针,两个整型,分布表示 cap、len
上文中提到无法直接修改 map 中的 struct,那么下面的程序是否合法?为什么?
1 m := map[int][]int{1: {1, 2, 3}}
2 m[1][0] = 11
3 fmt.Println(m)内存对齐
struct 中的字段会按照机器字长进行对齐,所以在性能要求比较高的地方,可以尽量把相同类型的字段放一起。
1 fmt.Println(
2 unsafe.Sizeof(struct {
3 a bool
4 b string
5 c bool
6 }{}),
7 unsafe.Sizeof(struct {
8 a bool
9 c bool
10 b string
11 }{}),
12 )上述代码会依次输出 32 24 ,下面的图示清晰的展示了两个顺序的 struct 在内存中的布局:(图片来源)
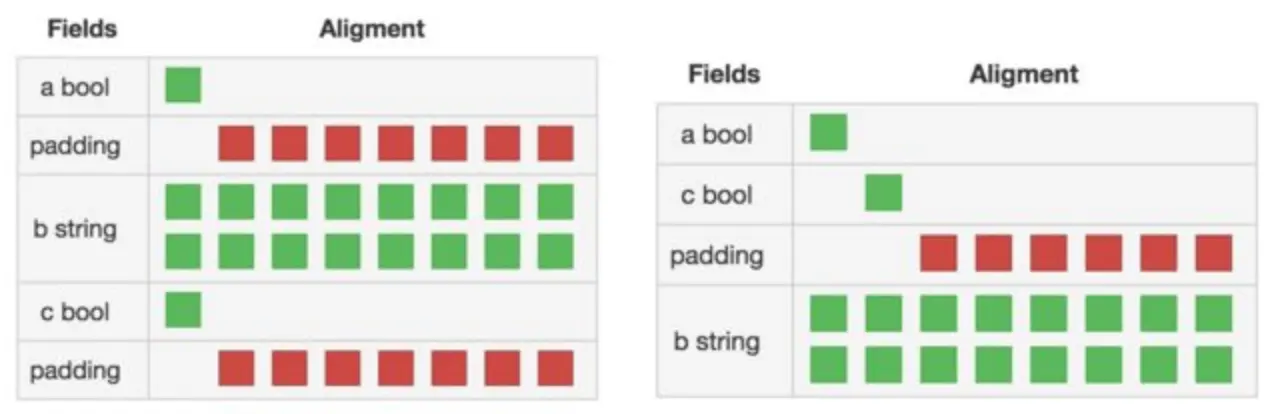
最后,读者可以思考下面代码的运行结果:
1 fmt.Println(
2 unsafe.Sizeof(interface{}(0)),
3 unsafe.Sizeof(struct{}{}),
4 )Interface
如果说 struct 是对状态的封装,那么 interface 就是对行为的封装,是 Go 中构造抽象的基础。由于 Go 中没有 oop 的概念,主要是通过组合,而非继承来实现不同组件的整合,比如 io 包下的 Reader/Writer。 但就组合来说,并没有什么优势,Java 中也可以实现,但 Go 中的隐式“继承” 让组合变得十分灵活。
Embedded struct
下面通过一示例进行说明:
1type RecordWriter struct {
2 code int
3 http.ResponseWriter
4}
5
6func (rw *RecordWriter) WriteHeader(statusCode int) {
7 rw.code = statusCode
8 rw.ResponseWriter.WriteHeader(statusCode)
9}
10
11func URLStat(w http.ResponseWriter, r *http.Request, next http.HandlerFunc) {
12 // if w.WriteHeader isn't called inside handlerFunc, 200 is the default code.
13 rw := &RecordWriter{ResponseWriter: w, code: 200}
14 next(rw, r)
15 metrics.HTTPReqs.WithLabelValues(r.URL.Path, r.Method, strconv.FormatInt(int64(rw.code), 10)).Inc()
16}上述代码片段为 negroni 中的一个 middleware,用来记录 http code。自定义 Writer 通过嵌入 ResponseWriter,实现了 ResponseWriter 接口,然后通过重写 WriteHeader 的方式来实现业务需求,由于需要改变状态,所以采用指针类型 *RecordWriter 来作为 receiver,整个实现非常简洁扼要。
New func type
第二个示例是关于如何通过自定义 type,来达到简化 err 处理的目的。在 net/http 中,handlerFunc 没有返回值,这就导致在每个异常处理的后面加上一个空的 return 来中止逻辑处理,这样不仅繁琐,还容易遗漏,
1func viewRecord(w http.ResponseWriter, r *http.Request) {
2 c := appengine.NewContext(r)
3 key := datastore.NewKey(c, "Record", r.FormValue("id"), 0, nil)
4 record := new(Record)
5 if err := datastore.Get(c, key, record); err != nil {
6 http.Error(w, err.Error(), 500)
7 return
8 }
9 if err := viewTemplate.Execute(w, record); err != nil {
10 http.Error(w, err.Error(), 500)
11 }
12}这时便可通过自定义新类型来解决这个问题:
1type appError struct {
2 Error error
3 Message string
4 Code int
5}
6type appHandler func(http.ResponseWriter, *http.Request) appError
7
8func (fn appHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
9 if e := fn(w, r); e != nil { // e is *appError, not os.Error.
10 c := appengine.NewContext(r)
11 c.Errorf("%v", e.Error)
12 http.Error(w, e.Message, e.Code)
13 }
14}
15
16func viewRecord(w http.ResponseWriter, r *http.Request) appError {
17 c := appengine.NewContext(r)
18 key := datastore.NewKey(c, "Record", r.FormValue("id"), 0, nil)
19 record := new(Record)
20 if err := datastore.Get(c, key, record); err != nil {
21 return appError{err, "Record not found", 404}
22 }
23 if err := viewTemplate.Execute(w, record); err != nil {
24 return appError{err, "Can't display record", 500}
25 }
26 return appError{}
27}
28
29mux.HandleFunc("/view", appHandler(viewRecord))可以看到,上述示例通过定义 appHandler 新函数类型,并隐式“继承” http.Handler 接口来达到了统一集中处理 err 的需求。该实现漂亮的地方为函数增加新类型,且函数签名与 ServeHTTP 一致,这样就可以直接复用参数。对于初学者来说,可能没想到也可以给 func 类型来定义方法,但是在 Go 中,可以给任何类型增加方法。
之前在网上看到一些框架,采用 panic 的方式来简化 err 处理,感觉这属于对 panic 的滥用,先不说对性能是否有损耗,更主要的是破坏了 if err != nil 的处理方式。希望读者在后续处理繁琐的逻辑时,多去考虑如何抽象新类型来解决。
总结
Go 的精妙设计保证了其简洁的特性,而且这些特性可能和传统的 oop 不同,这对于从这些语言转过来的读者来说会采用旧思维去思考问题,这无可厚非,但作为优秀的 Go 程序员,更多的需要从 Go 自特点来考虑问题,这样就不至于产生“为什么 XX 特性在 Go 中没有”的疑惑,要知道 Go 的作者可是 Rob Pike, Ken Thompson:-)
如果读者阅读/实现过基于 interface 的精巧设计,欢迎留言分享。
参考
- https://go101.org/article/value-part.html
- https://github.com/tyranron/golang-sizeof.tips/blob/master/internal/parser/types.go
- https://blog.golang.org/error-handling-and-go
- https://medium.com/a-journey-with-go/go-should-i-use-a-pointer-instead-of-a-copy-of-my-struct-44b43b104963
- https://research.swtch.com/godata