2020 年 12 月 26/27 日,第一届 Rust China 大会在深圳隆重开幕,来自五湖四海的 Rustacean 相聚于此,畅聊使用 Rust 构建应用的心得与挑战。参会人员除了企业开发者、独立开发者外,还有来自高校的师生,演讲主题涵盖广泛。我有幸参与了这次大会,本文就来总结此次参会的经历,让更多的读者一起享受这次饕餮盛宴。
同时,也希望通过本文,激发读者学习 Rust 的兴趣,毕竟 Rust 是近几年最受程序员喜爱的语言。
此次大会议程两天,共有 36 个演讲,基本上 30 分钟一个,内容非常多,想在一篇文章里涵盖全部演讲会显得有些臃肿,而且更重要的是,很多领域对我来说也比较陌生,因此这里会对演讲进行分类,重点聊聊对我感兴趣的几个演讲。读者可以根据喜好自行学习,所有的演讲文稿/视频均可在官方网站查阅。
其次,对于本次大会接触的几个开源项目,使用 loc 进行代码量统计(截止 2020/12/29 主干分支的提交)。尽管代码量的意义非常局限,但代码量可以对陌生项目有直观印象,而且对于 Rust 这个新生代的编程语言来说,也需要在构建大型系统中去“提炼“自身,到底谁会是 Rust 的杀手锏应用(killer app),让我们拭目以待。
数据库系统
数据库相关领域,通常是系统语言的“试金石”。目前业界主流使用 C/C++ 编写,既然 Rust 的目标是下一代的系统语言,数据库领域是其落地的最佳场景之一。本次大会有三个与数据库相关的演讲,下面来一一介绍
使用 Rust 构建高性能时序数据库 CeresDB
from Ant Group (蚂蚁集团)
这个演讲是我们组的,基于对「安全」、「高性能」的追求,选择了 Rust 来构建时序数据库,目前已在蚂蚁主站落地使用。本次演讲主要分享以下几点实践经验:
- 针对 LSM 类型存储引擎优化编码。
timestamp+series_idorseries_id+timesample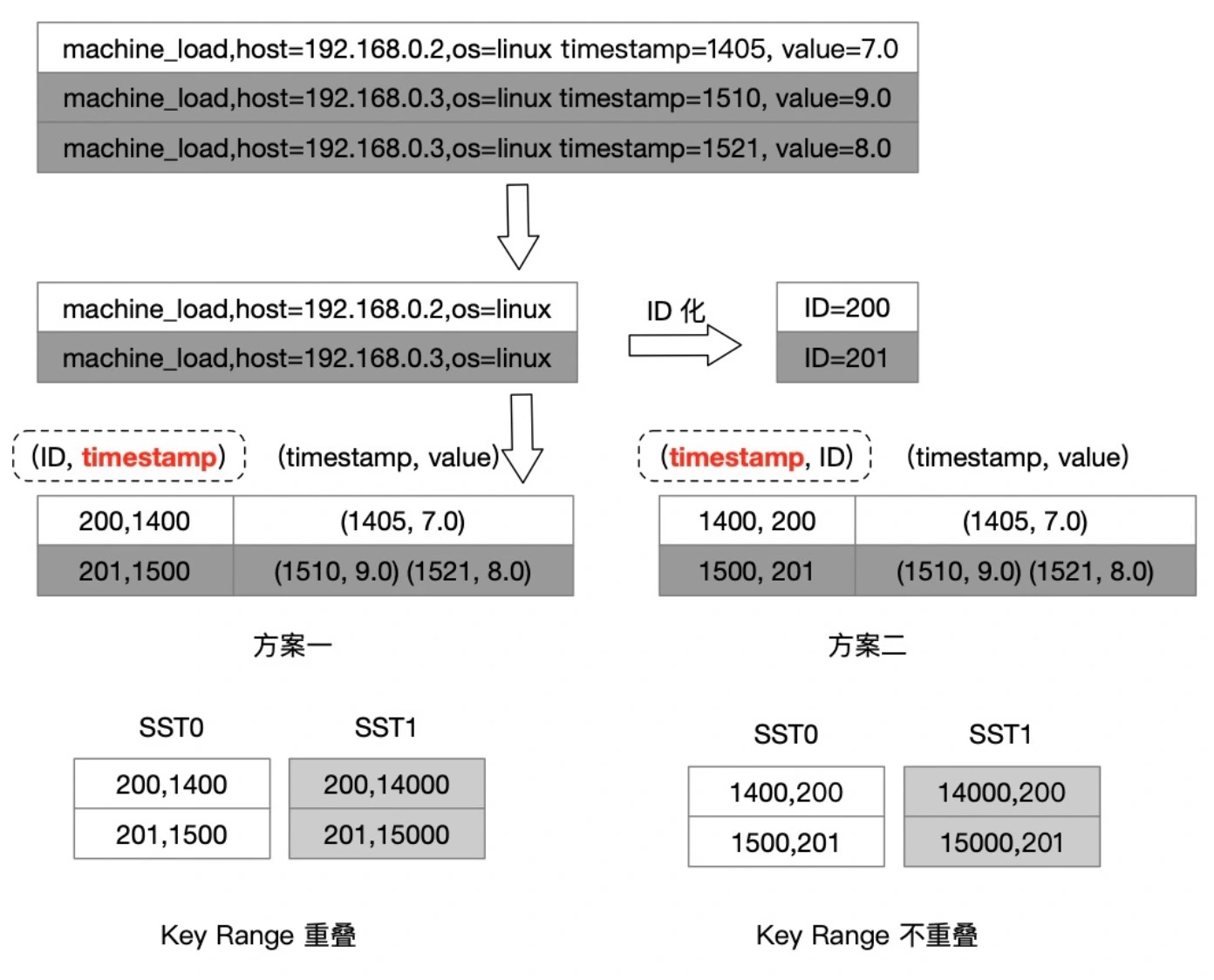
- 查询时合并小请求,减少不必要的线程切换
- 充分利用内存。借鉴 Facebook Gorilla 实现内存时序数据库,并且支持毫秒精度与更新。
在使用 Rust 的过程中,遇到过下面几个坑:
- 忽视 match 作用域,导致死锁,具体可参考:Drop order in Rust: It's tricky
- match enum 时使用全匹配,导致业务逻辑变更时部分分支出现 bug
- 误认为
None大小为 0
我们在生产环境遇到过更复杂的问题,比如 Rayon 线程使用不当导致的 stackoverflow, 但碍于篇幅,就没在这次演讲中讲述,后面有机会再聊。这里建议读者在项目中开启 clippy 来保障代码质量。
高性能 Rust tracing 库设计
提到 Rust,国内首先联想到的公司就是 PingCAP。除了贡献各种好用的库外,PingCAP 的 TiKV 证明了使用 Rust 开发大型数据库系统的可行性。根据 loc 统计,TiKV 代码量大概在二十多万行左右:
1--------------------------------------------------------------------------------
2 Language Files Lines Blank Comment Code
3--------------------------------------------------------------------------------
4 Rust 754 278023 27225 19027 231771
5 JSON 7 56136 0 0 56136
6 Toml 60 4410 554 786 3070
7 Markdown 9 1505 316 0 1189
8 YAML 2 393 27 0 366
9 Makefile 2 405 76 121 208
10 C 1 204 14 29 161
11 Bourne Shell 7 266 47 65 154
12 Python 1 128 16 12 100
13 Docker 1 110 24 25 61
14--------------------------------------------------------------------------------
15 Total 844 341580 28299 20065 293216
16--------------------------------------------------------------------------------此次 PingCAP 带来的演讲是一个小巧精悍的追踪库 minitrace,主要思路:
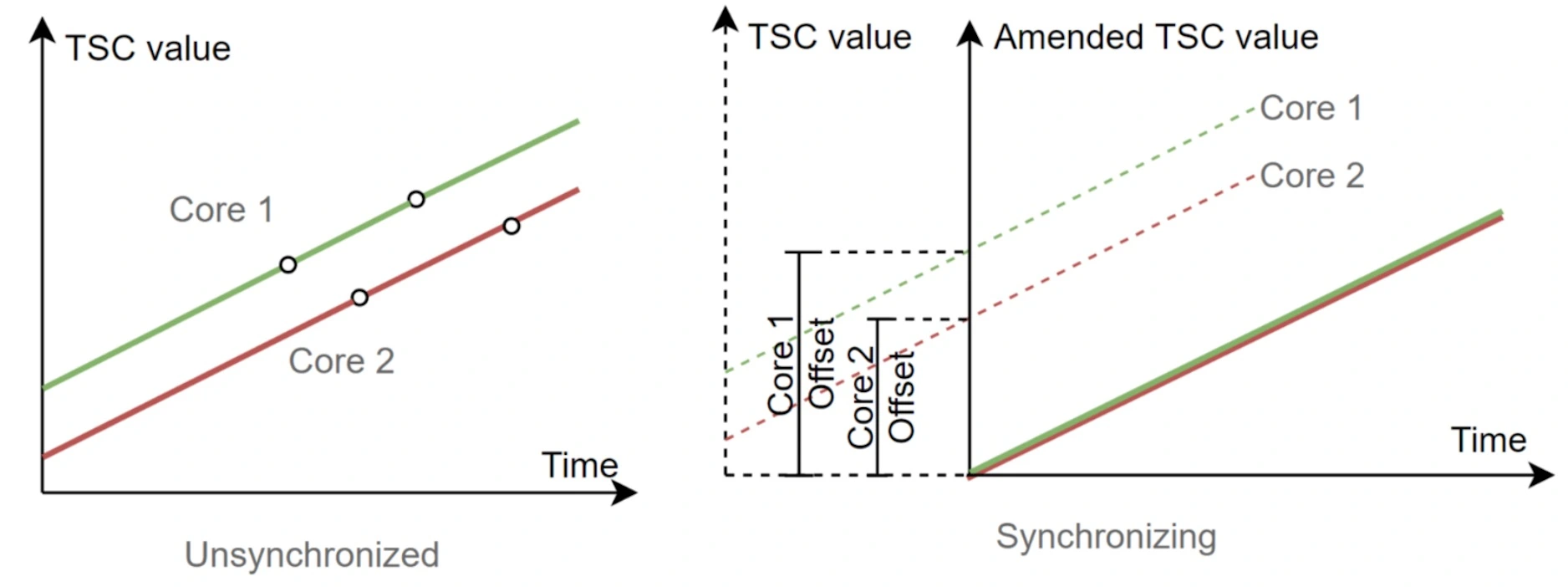
- 避开调用标准库
Instant::now的开销(25ns),直接调用 TSC 指令(x86 架构下,单次耗时 5ns) - 通过绑线程(sched_setaffinity)的方式,同步多线程的时间获取
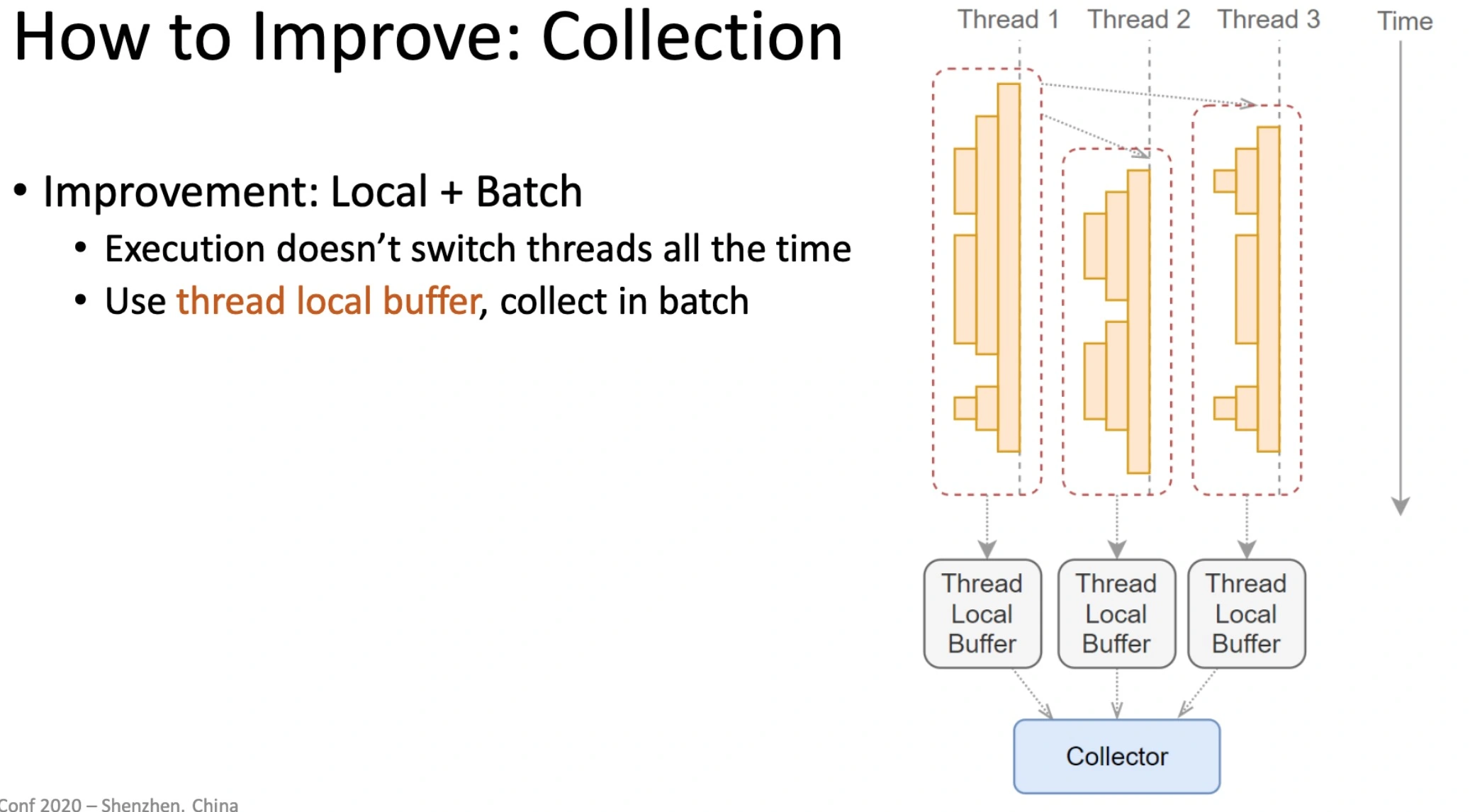
- 在收集时,首先通过
thread_local进行线程内收集,然后在批量收集多个线程内的结果
关于 TiKV 更多的技术介绍,可以参考其官方博客。
基于 Rust 构建高性能新型开源数据仓库 TensorBase
from Jin Mingjian (金明剑)
TensorBase 是讲师个人项目,一个高性能、低成本的数据仓库。讲师具备多年相关领域经验。比较遗憾的是演讲时间较短,很多点都是“蜻蜓点水”,没有深入讲述。
讲师首先分析了现代软硬件的现状足以满足数据仓库的需求,比如内存容量不再是瓶颈;新一代的硬件 NVME SSD 性价比也不再让企业望而却步;程序员需要刷新对现代硬件的认识:
- Tens of Billion calculations done in one second for a single modern core, trillions/s for single package
- Scalability does not mean high performance, and possibly be low performance and thus cost expensive
- Petabytes(PB) level Data can be hold in a single modern node
- Current OLAPs are far from taking use of the full capabilities of modern CPU
- Speed of IO is on par with or faster than that of memory (in throughput)
- In memory OLAP is economically cost prohibitive for massive data analysis
在架构相关内容里,介绍的相关技术也是数据库领域中比较成熟的技术,比如 JIT 编译、查询改写(对应文稿中 Layered IR),不清楚 TensorBase 是如何做到比 ClickHouse 有四五倍的性能提升。GitHub 上开源版本的 loc 只有八千行,不像是完整代码,而且讲师也提到写入流程是用 Rust 实现,而查询部分是用 C++/Rust 混合实现的,C++ 的部分目前应该没有开源出来。
最后讲师介绍了 Engineering Rust 的一些经验,总的来看,Rust 作为底层的系统语言,提供了很多高级语言具备的功能,比如 cargo 包管理、过程宏定义 DSL、零成本与 C 交互、禁止类型隐式转化,但 Rust 作为一门年轻的语言,也存在一些工程化的问题,主要有:
- 过程宏学习成本高、调试难。可参考 #54140
- 没有一个好用的错误处理。可参考 Rust: Structuring and handling errors in 2020
生命周期使得编程更困难,代码更复杂。讲师这里推荐
Always recommends: to dance with, rather than to evade,不清楚讲师是怎么 dance 的😂,个人感觉一但把 struct 内的一个成员改为引用,代码写起来就非常恶心,rust-analyzer 核心开发者的一篇博客 Encapsulating Lifetime of the Field 提出一个规避方法,但感觉也不是很理想。讲师这里提到 TensorBase 用了两种策略来规避生命周期的问题:- Arena allocator: TensorBase IR
- Unsafe into C: TensorBase kernel algorithms in C
缺少清晰的内存模型。Channel 通过消息传递的方式来解决线程安全,对于高性能应用来说消息传递带来的拷贝代价太高,需要用 communicate by sharing memory 的方式来实现线程安全,目前 Rust 里面只能使用锁(Mutex),但锁的性能损耗比较高。Java 里面 happen-before 的内存模型则可以避免加锁的问题。可参考:
通过上面的内容可以看出讲师有非常深厚的功力,后面会持续关注这个项目的发展,争取揭开 TensorBase 的神秘面纱。
操作系统/文件系统
用 Rust 实现用户态高性能存储
DatenLord 是此次大会最为“硬”核的分享。DatenLord 和 TensorBase 的出发点类似,一开始都讲述了现代硬件性能已经越来越强劲,Linux 内核中的模块已经无法充分利用硬件性能,通过在用户态编写存储来绕过内核。这里有必要贴一下 Google 大神 Jeff Dean 提出的 Numbers Everyone Should Know,不过随着时间推移,这里面的数字可能已经不准确,因此有人制作了不同年份的可视化网站来展示:

讲师这里也提到了使用 Rust 进行系统编程的体验,和上面 TensorBase 讲师的总结差不多:
| 优点 | 缺点 |
|---|---|
| 强规约(类型安全) | 宏过于灵活 |
| 函数式风格 | 异步场景生命周期过于复杂 |
| FFI 容易出错 | |
| 错误处理、日志处理 verbose |
讲师也尝试使用 Rust 直接进行硬件编程,由于 LLVM 支持编译输出硬件描述语言 HDL,理论上这条路是可行。由于我对这块了解不多,这里不再过多介绍。DatenLord 开源版本的 loc 在一万行左右
1--------------------------------------------------------------------------------
2 Language Files Lines Blank Comment Code
3--------------------------------------------------------------------------------
4 Rust 29 16621 1187 2401 13033
5 YAML 3 1299 33 190 1076
6 Protobuf 2 1522 186 891 445
7 Markdown 2 256 60 0 196
8 Toml 3 111 9 2 100
9 Bourne Shell 2 98 18 6 74
10 Docker 1 24 4 0 20
11 INI 1 26 4 4 18
12--------------------------------------------------------------------------------
13 Total 43 19957 1501 3494 14962
14--------------------------------------------------------------------------------基于 Rust 语言的操作系统内核
from Tsinghua University
除了上面这个演讲外,清华还有一个 《rCore:Rust 操作系统内核的探索 + MadFS:小巧精悍的分布式文件系统》的演讲,也是操作系统范畴,这里归为一个。
Linux Kernel 发展多年,代码行数已有 26,132,637 行(2018),由于内核是采用“不安全”的 C 编写,导致在如此庞大的系统中很难发现漏洞,因此业界一直在探索其他架构,比如微内核、多内核(Barrelfish/HeliOS)、LibOS、ByPass Kernel。 rCore 是清华内部自主开发,用于探索使用 Rust 构建基于 RISC-V 架构的操作系统,目前主要用于教学。
Google 在 16 年推出的 Fuchsia 操作系统,其内核 Zircon 采用微内核架构,Rust 虽然是 Fuchsia 的开发语言之一,但在 Fuchsia Programming Language Policy 明确提到没在 Zircon 中使用
The Zircon kernel is built using a restricted set of technologies that have established industry track records of being used in production operating systems.
2020 年,清华的师生开始研究 Zircon,在 rCore 的基础上开发 zCore,兼容 Zircon。没想到清华的教学这么先进!给清华的师生点赞👍
在 Fuchsia 中,Rust 的 loc 有近一百万行(除去 third_party),可见 Rust 在 Fuchsia 中被重度使用,那 Linux 支持 Rust 还远嘛?
1--------------------------------------------------------------------------------
2 Language Files Lines Blank Comment Code
3--------------------------------------------------------------------------------
4 C++ 8042 1816064 290815 165840 1359409
5 Rust 3570 1148496 107910 115386 925200
6 C/C++ Header 6133 669094 120848 145137 403109
7 Go 960 181372 21636 16925 142811
8 Markdown 1553 163623 42306 0 121317
9 C 402 103873 15068 13679 75126
10 Dart 355 45281 5737 6346 33198
11.....省略其他统计...
12--------------------------------------------------------------------------------
13 Total 22850 4305722 624242 487881 3193599
14--------------------------------------------------------------------------------区块链
两天的演讲听下来,第一感觉就是 Rust 仿佛是为区块链而生,议题中有五个来自区块链的企业。
区块链作为一门新生技术,依附于比特币而为大众所知。主要应用场景主要金融领域,对「安全」有极高的要求,而此特点正符合 Rust 的设计理念:
Rust - A language empowering everyone to build reliable and efficient software.
RustCC 社区创办者 Mike Tang 在《当区块链遇上Rust》一文中详细介绍了 Rust 为什么适合区块链开发,感兴趣的读者可参考,这里不再赘述。相关演讲有:
Substrate 中的 Rust 设计模式
from Parity Asia
主要分享了 newtype/builder 设计模式,然后对“宏”元编程进行了大笔墨介绍。对于接触过 Lisp 的我来说,宏是在熟悉不过的了。Rust 的宏相比 C/C++ 中简单的文本替换来说无疑是巨大进步,但是由于 Rust 语法不具备同像性(homoiconicity),导致写宏的过程比较痛快,需要去区分 ident/item/block 等语法单元,对于简单的宏还好,对于稍微复杂一点 DSL,就没有可读性了。
印象中本次大会还有四五个演讲也提到了宏的便利性,但希望读者能意识到宏带来的 调试复杂性 ,慎重使用。这里顺便分享一个我用的比较多的宏:
1#[macro_export]
2macro_rules! map(
3 { $($key:expr => $value:expr),+ } => {
4 {
5 let mut m = ::std::collections::HashMap::new();
6 $(
7 m.insert($key, $value);
8 )+
9 m
10 }
11 };
12);
13// 使用方式
14map!{ "a" => 1, "b" => 2 }Rust 和 BPF
from Solana
BPF 是新一代的程序诊断工具,相当于在 Linux 内核中嵌入了一个锚点,可以执行用户编写的脚本程序,最初用来捕获数据包,后来功能逐渐增加,诞生了像 BCC 这样的开发套件简化 BPF 的编写。
来自 Solana 的工程师分享了如何在其区块链上嵌入使用 Rust 编写的 BPF 虚拟机来支持智能合约(如果把区块链比做数据库,那么智能合约大概相当于 UDF)。Solana 在社区开源版本的基础上,做了下面几个修改:
之前没接触过 BPF,后面会抽时间看看如何用它来定位线上问题。 与区块链相关的其他演讲还有下面几个,这里不做讲述,感兴趣读者可自行阅读。
- 《Rust, RISC-V 和智能合约》from 秘猿科技
- 《经验教训-使用 Rust 构建去中心关键任务系统》from Near & Cdot
- 《用过程宏简化 Rust 代码》from 猎币科技(Bifrost)
WASM
- 《云计算中的 Rust 和 Wasm》from Second State
- 《WebAssembly - 现在和未来》from PayPal
与区块链类似,WebAssembly(简称 WASM)也是近几年兴起的技术,为提高 Web 性能而生。它可以看作是一种新的运行时(runtime),可以提供与 C/C++ 类似的性能,同时 WASM 可以与 JavaScript 互操作,这样可以最大程度利用现用模块。
由于 WASM 的首要诉求是高性能,很多开发者选择了 Rust。同时 Rust 也把 WASM 作为首要支持的平台,互利共生。更多 WASM 知识,可参考:
华为
此次大会,华为演讲有四个,可以看出华为内对 Rust 的探索是非常积极的。
虚拟化:Rust 系统编程在 StratoVirt 中的实践
StratoVirt 是一个面向面向云数据中心的企业级虚拟化平台,实现了一套架构,支持虚拟机、容器、Serverless三种场景。 一些 Rust 工程经验:
- 单线程 epoll 处理 IO:降低内存开销
- 使用 error_chain 处理错误,代码优雅。(PS:印象中这是大会唯一一个说 Rust 错误处理优雅的 😂)
缺点和其他讲师差别不多,集中在 Unsafe/锁的使用与性能上,此外还提到了热补丁技术,对于企业级虚拟化平台来说,能够在线打补丁是非常重要的。
讲师还提到 Rust 语言的一个不足,即 trait object 不能组合,即 Box<Write + Read> 是不允许的,与此相关的问题还有:subtrait 不能转为 trait 类型。
这两个问题其实是一致的,与 trait object 实现机制有关,更准确的说是 vtable 的实现,这个话题比较复杂,这里不展开讨论,感兴趣的读者可阅读下面的链接:
目前这两个问题的解法如下:
- 对于不能组合的问题,可以通过定义另外一个 trait object 来解决
- 对于不能转化的问题,通过定义个 AsTrait 来解决,可参考这里。
StratoVirt 代码量在 2 万行左右。
1--------------------------------------------------------------------------------
2 Language Files Lines Blank Comment Code
3--------------------------------------------------------------------------------
4 Rust 68 24287 2632 4564 17091
5 Markdown 7 1324 330 0 994
6 Toml 6 147 23 3 121
7 JSON 1 21 0 0 21
8 Makefile 1 11 2 0 9
9--------------------------------------------------------------------------------
10 Total 83 25790 2987 4567 18236
11--------------------------------------------------------------------------------Rust 可信编程在华为
该讲师从宏观角度谈了华为对 Rust 的探索,包括:代码自动生成、支持 AArch64 指令集,在 Rust 社区方面,起草相关编码规范,安全代码度量工具 geiger 等。
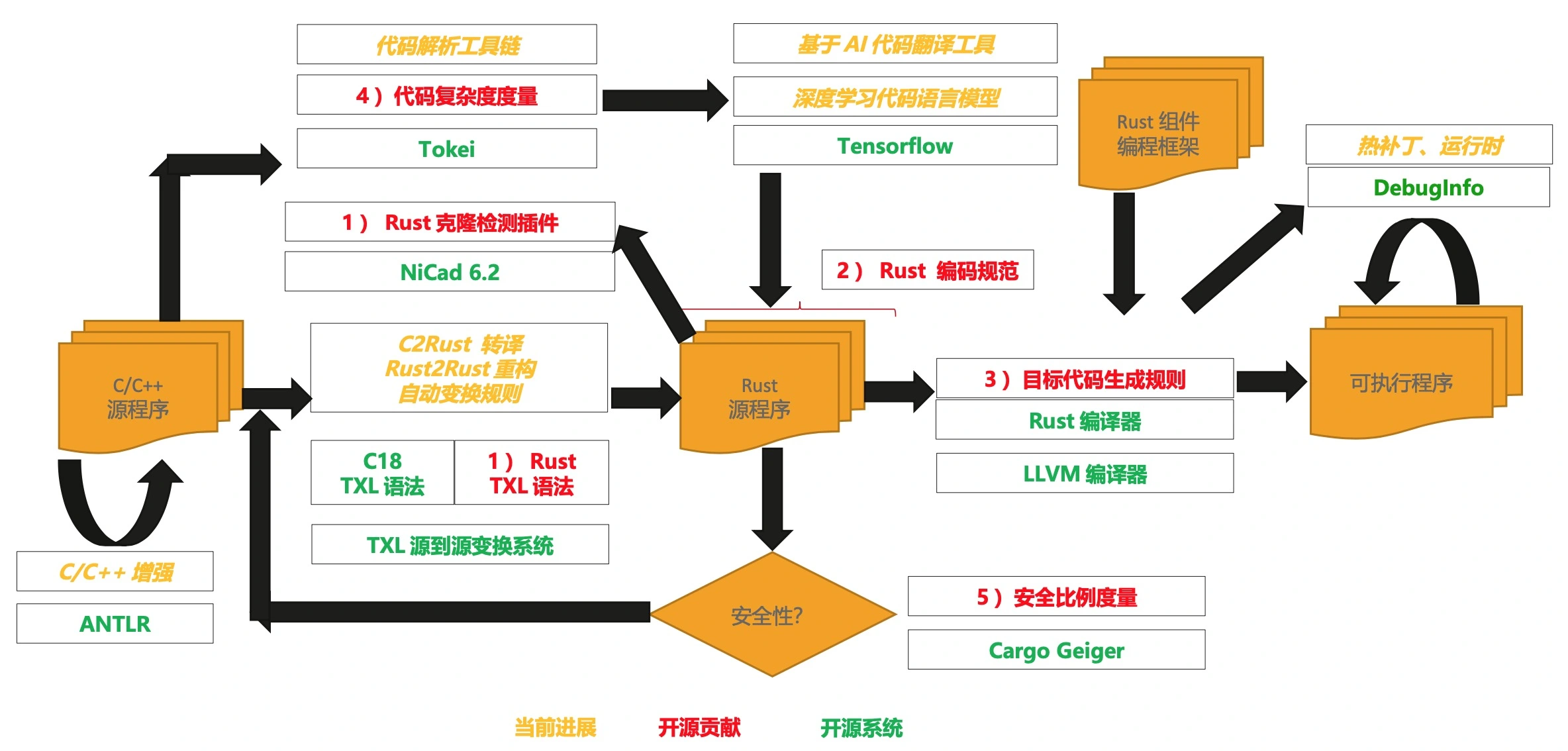
虽然这个演讲只有十几分钟,但是能感觉到华为对 Rust 的投入。此外华为还有下面两个演讲,这两个方向不是很了解,这里不再讲述。
- 《Rust 和 ROS 机器人开发》
- 《Rust 数值计算生态盘点》
飞书
- 《Rust Code Analysis 实践》
- 《Rust在飞书客户端的智能化探索》
飞书团队主要其在 SDK 中使用(非 UI 部分),作为跨平台的实现。个人感觉这种做法还是比较小众的,本次大会的分享没有介绍其背景,重点介绍了如何利用神经网络来预期用户可能会打开哪些会话,做到智能加载消息列表。Infoq 上的 Rust 跨平台客户端开发在字节跳动的实践 有比较详细的介绍:
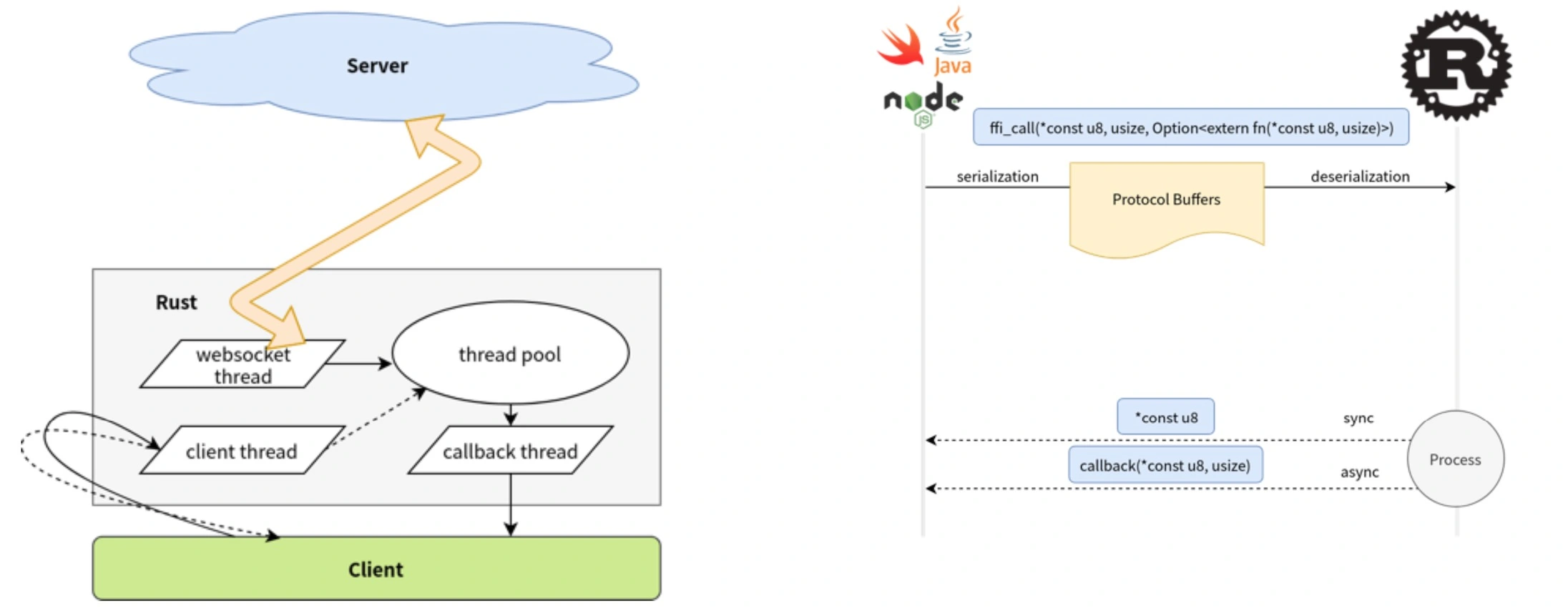
一些工程经验:
- 在 17 年开始引入 Rust,看重与 C++ 互调用以及具备高级语言的特性
- Rust 生态比较年轻,压缩库不支持 NonCompressed DEFLATE(18年的事情)
- Rust 一直在演进,为了跟进社区,需要重构代码,比如错误处理从 error-chain 转到 failure。这和上面 TensorBase 的体验类似
FFI 的不安全性
- Protocol Buffer 不适合大数据量与高频的函数调用,Cap'n Proto/FlatBuffers 可以减缓这个问题
- 如果性能需要,直接使用 raw 类型
- 代码体积大,主要是范型的问题
- Rust 使用的 LLVM 与 Apple 自动的版本不一致,bitcode 不兼容
其他演讲
- 《Rust 作为汽车软件主语言的探索 》from AICC (国汽智控)
- 《Rust 语言与嵌入式开发》from HUST (华中科技大学)
- 《用 Rust 设计高性能 JIT 执行引擎》from NUAA(南京航空航天大学)GitHub
- 《机器人:Slamtec 的 Rust 实践 》from Slamtec (思岚科技)
- 《游戏引擎:Rust 游戏引擎开发》from Aberystwyth University(亚伯大学)
- 《加密算法:椭圆曲线的加密算法的最佳实现和高效的 SM2 算法》 from Rivtower (溪塔科技)
- 《Async-graphql 的介绍与实现》from 老油条 GitHub