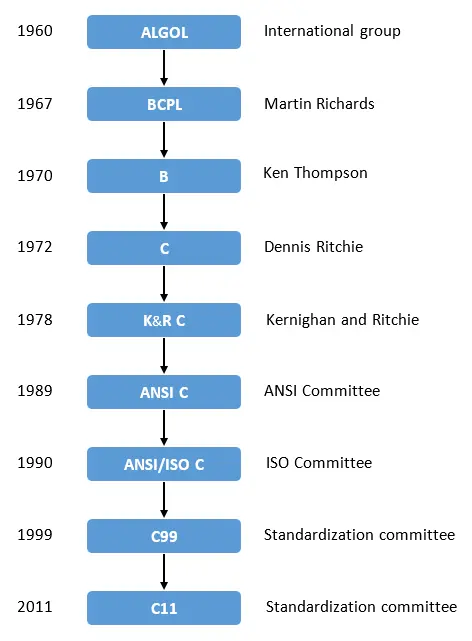
即使从 K&R C 的 1978 年开始算起,到 2022 年 C 也有 44 年的历史了。
不知 C 在读者心中是什么样子,在笔者印象中,C 的表达力很差,只有数组与指针两种高级数据结构,标准库小并且有很多历史问题,没有包管理机制,最致命的是,需要手动管理内存,现代年轻程序员很难对 C 感兴趣了,可选择的高级语言太多了,比如:如日中天的 Java,后起之秀的 Go/Rust,为什么要去选择 C?
笔者也是最近一年有重新学习 C 的想法,主要原因是现在的工作与数据库相关实现,而老牌数据库像 PostgresQL、MySQL 等都是用 C 来实现的,虽然如今新兴的数据库有更多的语言选择,但之前 C 在这方面积累了几十年的经验,不是轻易就能超过的,而且像数据库这类复杂的软件,即使采用相似的思路,性能也可能差距甚远。比如哈希函数的选择?冲突怎么解决?如何确定哈希桶大小?有了 C 语言底子,才有可能去看懂这些传统软件的实现过程。
背景介绍
为了体验 C 的开发体验,笔者先是看了 21st Century C 这本书,这本书比较短,可以很快看完,不过这本书讲的也比较浅,之前不了解 C 的工具链的话,看这本书会有所帮助,但对写 C 代码帮助有限,于是又重新温习了 C程序设计语言(第2版·新版),不得不说,即使这么多年了,这本书依然是学习 C 最好的教材,内容简洁、扼要,案例典型,全篇没有一句废话,这本书也比较短,不做习题的话,一周也可以看完。如果说这本书有缺点,那就是变量名不需要在函数一开始全部定义出来了,现在的 C 编译器比之前先进了不少。
有了 K&R C 的底子,就可以直接开始实战了。笔者最近一个月用 C 开发了一个 2K 行的项目:jiacai2050/oh-my-github,不算太 trivial,主要是想从这个项目中体验以下内容:
- C 的开发流程,熟悉相关工具链
- C99/C11 的语言特性
- C 编码风格要领,如何设计 API 才能避免使用者踩坑
下面章节就针对这三点,总结下近几个月的收获。由于接触时间有限,文中难免有不足之处,欢迎读者批评指正。
工具链
首先聊聊工具链。开发一个正式项目前,有一些比较繁琐的事情要做,比如配置开发、调试环境,安装依赖等。对于 C 来说,LSP 支持的比较好,笔者使用的 language server 是 clangd,查看变量定义、查看引用、自动补全等功能都支持。clangd 使用 compile_commands.json 这个文件做配置,一些构建工具可以直接生成它,对于简单的个人项目,也可以直接用 compile_flags.txt 做配置,使用样例:
-I /opt/homebrew/Cellar/jansson/2.14/include -I /opt/homebrew/Cellar/pcre2/10.40/include
对于老牌 C 程序员来说,他们可能会更熟悉 universal-ctags/ctags,遇到 LSP 不能胜任的时候,也可以试试它。
包管理
开发工具配置好后,在正式写代码之前,往往还需要安装依赖,这就涉及到一个重要话题:包管理。
包管理最重要的一点是保证每个项目的依赖是固定的,即 reprodubile build,这不是个简单的事情,在直接、间接依赖某库多个版本时,如何选择正确的版本,npm2 那种把每个库的依赖单独下载是一种解法,Go 的 Minimal version selection 也是一种解法。
在介绍 C 如何进行包管理前,先来回顾下 C 代码的组织方式。一个 C 项目主要有两类文件:
.h头文件,主要用来做声明,包括函数签名、类型等.c源码文件,主要用来对头文件中的声明提供实现
这两类文件在构建的不同阶段会用到,具体可参考下面的图片(来源):
可以看到,头文件只在第二个阶段(即预处理)会用到,源码文件只会在第三个阶段(即编译)时用到,第四、五两个阶段会把用户自己的代码与第三方依赖的代码链接的一起,形成最终的可执行文件。
当一个项目作为类库时,一般不直接提供源码,而是会提供源码文件对应的:
.so共享库(shared object)或.a静态库(static library,使用 archive 命令创建)
这样一方面是保护源代码不泄漏,另一方面是加速构建流程。用户只需要编译自己的代码即可,三方依赖不需要反复编译。
对于 C 而言,没有严格的包组织方式,只要能在编译、链接期间找到对应的文件即可。社区内有些包管理器,比如 vcpkg、conan-io/conan、CMake 等。对于个人项目来说,也可以选择下面这种方式:通过操作系统提供的工具(brew 或 apt 等)安装依赖,然后手写 Makefile 来配置编译、链接参数。
这种方式看似简陋,但是能比较有效地解决问题,再加上容器技术,也能比较好做到版本隔离。唯一不足的是无法准确指定依赖版本。
Makefile
下面来介绍下 Makefile 的基本使用,一个功能完备的示例可参考:Makefile。
1P = program_name
2OBJECTS = main.o
3CFLAGS = -g -Wall -O3
4LDLIBS =
5CC = gcc
6$(P): $(OBJECTS)
7 $(CC) $(OBJECTS) $(LDFLAGS) -o $(P)
这是一个比较基础的 Makefile 模板,Makefile 有默认的规则把 .c 文件转为 .o 文件,大致的命令:
1%.o: %.c
2 $(CC) $(CFLAGS) -c $< -o $@
因此可以通过 CFLAGS 来定义编译期的参数。Makefile 中有几个常用的变量:
$@表示 target name$*表示 target name without suffix$<表示 target dependencies,即冒号后面的内容
手动配置 CFLAGS 不仅繁琐,还容易出错,可以借助 pkg-config 这个工具来简化配置,比如安装了依赖 libcurl ,可以用下面的方式来找到它的编译参数与链接参数:
1# pkg-config --cflags --libs libcurl
2-I/usr/include/aarch64-linux-gnu -lcurl-I用来设置头文件的搜索目录-l用来指定链接器要链接的类库
一般 C 类库分发时,会提供对应的头文件与编译好的共享库或静态库,在 Debian 系统下,可以通过下面的命令查找 libcurl4-openssl-dev 所安装的文件:
1dpkg -L libcurl4-openssl-dev
2
3/usr/include/aarch64-linux-gnu/curl/curl.h
4/usr/include/aarch64-linux-gnu/curl/easy.h
5/usr/lib/aarch64-linux-gnu/libcurl.a
6/usr/lib/aarch64-linux-gnu/libcurl.so至于链接器选择静态库还是共享库,每个链接器的做法不一致,可参考对应平台的文档。GNU ld 的做法
是通过 -l: 的方式来指定静态库,比如: -l:libXYZ.a 只会去找 libXYZ.a ,而 -lXYZ 则会扩展成 libXYZ.so 或 libXYZ.a 。参考:
语言特性
解读指针声明
指针作为 C 中最重要的一类型,往往会给初学者造成较大困扰,不仅仅是使用上,光是解读指针定义就不是件容易的事情。比如:
1int *ptr;
2int *ptr2[10];ptr 比较好理解,是指向 int 类型的指针,那 ptr2 呢?是指向数组的指针,还是元素为指针的数组?
其实这个问题在 K&R C 这本书有一点睛之笔,即:
The syntax of the declaration for a variable mimics the syntax of expressions in which the variable might appear.
也就是说,变量的声明语法,阐明了该变量在表达式中的类型。翻译过来比较绕,看几个例子就明白了:
1int *ptr;*ptr 是一个类型为 int 的表达式,因此 ptr 必须是指针,指向 int
1int arr[100];arr[i] 是一个类型为 int 的表达式,因此 arr 必须是数组,数组元素为 int
1int *arr[100];*arr[i] 是一个类型为 int 的表达式,因此 arr[i] 必须是指针,因此 arr 必须是数组,元素是 int 的指针。
1int (*ptr)[100];(*ptr)[100] 是一个类型为 int 的表达式,因此 ptr 必须是指针,指向一个 int 类型数组
1int *comp()*comp() 是一个类型为 int 的表达式,因此 comp() 必须返回一个 int 指针,因此 comp 是一个函数,返回值是 int 的指针
1int (*comp)()(*comp)() 是一个类型为 int 的表达式,因此 *comp 必须是一个函数,因此 comp 是一个函数指针
通过上面的解释,如果读者一时没有理解也不要紧,平时写代码用到时再来揣摩其中的奥妙。对于复杂的声明,一般推荐用 typedef 的方式。比如:
1typedef int *int_ptr;
2typedef int_ptr array_of_ten[10];
3
4
5array_of_ten a1 = ...;通过这种方式定义的 a1 理解起来就没什么难度了,它首先是一数组,数组的元素是指向 int 的指针。K&R C 有一个程序,可以将复杂声明转为文字描述:K&R - Recursive descent parser。
这里有一个在线的版本:
固定宽度的类型
C99 的 stdint.h 中新增了以下类型,来解决之前整型大小不固定的问题:
- int8_t、int16_t、int32_t、int64_t
- uint8_t、uint16_t、uint32_t、uint64_t
- int_least8_t、int_least6_t、int_least32_t、int_least64_t
- int_fast8_t、int_fast6_t、int_fast32_t、int_fast64_t
- uintmax_t、uintptr_t
内存管理
C 作为一门系统级语言,没有 runtime,通过 malloc 之类函数申请的内存需要程序员手动释放。这一点也是现在高级语言所尽力避免的,因为程序员相对计算机来说,是非常不可靠的。不过幸好 C 也再演进,在 GNU99 扩展中(clang 也支持),提供了一个 cleanup 属性来简化内存的释放。
先来看看没用 cleanup 之前怎么处理内存释放(完整代码):
1static char *request(const char *url) {
2 CURL *curl = NULL;
3 CURLcode status;
4 struct curl_slist *headers = NULL;
5 char *data = NULL;
6
7 curl_global_init(CURL_GLOBAL_ALL);
8 curl = curl_easy_init();
9 if (!curl)
10 goto error;
11
12 data = malloc(BUFFER_SIZE);
13 if (!data)
14 goto error;
15
16 ...... // 省略中间逻辑
17error:
18 if (data)
19 free(data);
20 if (curl)
21 curl_easy_cleanup(curl);
22 if (headers)
23 curl_slist_free_all(headers);
24 curl_global_cleanup();
25 return NULL;
26}request 函数是 C 中一个比较常见的做法,即函数出错时 goto 到统一地方,在那里统一进行内存清理。这种方式个人觉得比较丑陋,比较容易漏掉某个变量的释放。下面看看使用 cleanup 后的写法:
1void free_char(char **str) {
2 if (*str) {
3 printf("free %s\n", *str);
4 free(*str);
5 }
6}
7
8int main() {
9 char *str __attribute((cleanup(free_char))) = malloc(10);
10 sprintf(str, "hello");
11 printf("%s\n", str);
12 return 0;
13}
14
15// 依次输出:
16
17// hello
18// free hello
可以看到, str 在 main 函数退出前执行了 free_char 来进行资源使用。为了方便使用,可以通过 #define 定义下面的宏:
1#define auto_char_t char* __attribute((cleanup(free_char)))
2
3// 使用方式:
4auto_char_t str = malloc(10);需要明确一点:cleanup 只能用在局部变量中,不能用在函数参数、返回值中。因此一个完整的 C 项目还需要用其他手段来保证内存安全,主要的工具有 ASAN、valgrind,这两者目前不支持混用,读者可按情况选择。这里给出 valgrind 一个使用示例:
1valgrind --tool=memcheck --leak-check=full --show-leak-kinds=all ./$(CLI) /tmp/test.db在内存泄漏时,会有大致如下报告:
1==609== HEAP SUMMARY:
2==609== in use at exit: 276 bytes in 37 blocks
3==609== total heap usage: 35,019 allocs, 34,982 frees, 279,075,706 bytes allocated
4==609==
5==609== 48 bytes in 6 blocks are still reachable in loss record 1 of 3
6==609== at 0x4849E4C: malloc (vg_replace_malloc.c:307)
7==609== by 0x57DB83F: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
8==609== by 0x57DCE2F: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
9==609== by 0x5843C5B: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
10==609== by 0x57DB73F: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
11==609== by 0x57DC8DB: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
12==609== by 0x57D8443: gcry_control (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
13==609== by 0x4CE9BC3: libssh2_init (in /usr/lib/aarch64-linux-gnu/libssh2.so.1.0.1)
14==609== by 0x48D58CF: ??? (in /usr/lib/aarch64-linux-gnu/libcurl.so.4.7.0)
15==609== by 0x48831FB: curl_global_init (in /usr/lib/aarch64-linux-gnu/libcurl.so.4.7.0)
16==609== by 0x10A0AB: omg_setup_context (omg.c:184)
17==609== by 0x10DD0B: main (cli.c:19)
18
19==609== 84 bytes in 25 blocks are definitely lost in loss record 2 of 3
20==609== at 0x4849E4C: malloc (vg_replace_malloc.c:307)
21==609== by 0x10D86B: omg_parse_trending (omg.c:1116)
22==609== by 0x10DBEF: omg_query_trending (omg.c:1176)
23==609== by 0x10DD6B: main (cli.c:38)
24==609==
25==609== 144 bytes in 6 blocks are still reachable in loss record 3 of 3
26==609== at 0x4849E4C: malloc (vg_replace_malloc.c:307)
27==609== by 0x57DB83F: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
28==609== by 0x57DCE2F: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
29==609== by 0x5843C4F: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
30==609== by 0x57DB73F: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
31==609== by 0x57DC8DB: ??? (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
32==609== by 0x57D8443: gcry_control (in /usr/lib/aarch64-linux-gnu/libgcrypt.so.20.2.8)
33==609== by 0x4CE9BC3: libssh2_init (in /usr/lib/aarch64-linux-gnu/libssh2.so.1.0.1)
34==609== by 0x48D58CF: ??? (in /usr/lib/aarch64-linux-gnu/libcurl.so.4.7.0)
35==609== by 0x48831FB: curl_global_init (in /usr/lib/aarch64-linux-gnu/libcurl.so.4.7.0)
36==609== by 0x10A0AB: omg_setup_context (omg.c:184)
37==609== by 0x10DD0B: main (cli.c:19)
38==609==
39==609== LEAK SUMMARY:
40==609== definitely lost: 84 bytes in 25 blocks
41==609== indirectly lost: 0 bytes in 0 blocks
42==609== possibly lost: 0 bytes in 0 blocks
43==609== still reachable: 192 bytes in 12 blocks
44==609== suppressed: 0 bytes in 0 blocks可以非常清楚地看到泄漏的地方,然后按图索骥去修复相应逻辑即可。修复后的报告:
1==481== LEAK SUMMARY:
2==481== definitely lost: 0 bytes in 0 blocks
3==481== indirectly lost: 0 bytes in 0 blocks
4==481== possibly lost: 0 bytes in 0 blocks
5==481== still reachable: 192 bytes in 12 blocks
6==481== suppressed: 0 bytes in 0 blocks除了使用工具来避免内存问题,更优雅的方式是在设计 API 时就保证尽少地分配,区分好边界,这在后面 API 设计时会提到,这里不再赘述。以下链接有更多关于 cleanup 的讨论:
字符串
C 中没有字符串类型,只是定义了当字符数组的最后一个元素为 NULL 时,这个数组可以当作字符串使用,这种方式的字符串称为 Null-terminated byte strings。由于没有记录字符串长度,因此很多操作都需要 O(n) 的时间,最近一个比较有名的例子是 GTA 的开发人员,通过去掉 sscanf 将性能提升了 50%。
而且 C 中没有 StringBuilder 这种可变的字符串,执行一些像 replace/split 操作时需要手动申请内存,这不仅仅使用上很难受,更重要的是容易内存泄漏,出现安全问题。笔者在这里有两个推荐方式来简化 C 中字符串的处理:
尽量使用固定大小的局部变量
在进行一些字符串操作时,有时候不需要动态申请内存,直接用固定大小的栈内存即可,这样也省去了 free 的烦恼。比如:
1char url[128]; 2sprintf(url, "%s/user/repos?type=all&per_page=%zu&page=%zu&sort=created", 3 API_ROOT, PER_PAGE, page_num);- 尽量使用社区内成熟的字符串库,而不是
string.h比如 Redis 作者的 Simple Dynamic Strings,更多可参考:Good C string library - Stack Overflow 与之类似的,C 中也有 hashtable 的实现:
Raw String
在实际开发中,难免会用到一些较为复杂的字符串场景,其他编程语言会提供 raw string 来简化处理。在目前的 C 标准中,还不支持这种用法,但是 GNU99 扩展提供了这个功能:
1printf(R"(hello\nworld\n)");除了 GNU99 扩展的这种用法外,还可以利用 xxd 命令来将某个文件的内容嵌入 C 代码中,操作方式如下:
1echo hello > hello.txt
2xxd -i hello.txt
3
4# -i 参数会输出 C 头文件格式的变量定义
5unsigned char hello_txt[] = {
6 0x68, 0x65, 0x6c, 0x6c, 0x6f, 0x0a
7};
8unsigned int hello_txt_len = 6;需要注意到, hello_txt 没有以 NULL 结尾,这在某些场景下不是很方便,可以采用下面的命令来追加上:
1xxd -i hello.txt | tac | sed '3s/$$/, 0x00/' | tac > hello.h
2cat hello.h
3# 输出
4unsigned char hello_txt[] = {
5 0x68, 0x65, 0x6c, 0x6c, 0x6f, 0x0a
6};
7unsigned int hello_txt_len = 6;Designated Initializers
毫不夸张的说,这是 C99 中最让人兴奋的特性,它让 C 更像现代化语言的同时,也更加实用。
1int a[6] = { [4] = 29, [2] = 15 };
2// 等价于
3int a[6] = { 0, 0, 15, 0, 29, 0 };
4
5
6// 嵌套的结构
7struct a {
8 struct b {
9 int c;
10 int d;
11 } e;
12 float f;
13} g = {.e.c = 3 };在使用这种赋值方式时,没有被赋值到的字段,自动初始化成零值,这是非常重要的一点,对于指针来说,它会指向 NULL 而不是任意的地址。
static_assert
这是 C11 增加的功能,能够在编译期检查断言的真否:
1#include <assert.h>
2int main(void)
3{
4 static_assert(2 + 2 == 4, "2+2 isn't 4"); // well-formed
5 static_assert(sizeof(int) < sizeof(char),
6 "this program requires that int is less than char"); // compile-time error
7}Generic selection
C11 的这个特性在一定程度上支持了泛型编程。
1#include <stdio.h>
2#include <math.h>
3
4// Possible implementation of the tgmath.h macro cbrt
5#define cbrt(X) _Generic((X), \
6 long double: cbrtl, \
7 default: cbrt, \
8 float: cbrtf \
9 )(X)
10
11int main(void)
12{
13 double x = 8.0;
14 const float y = 3.375;
15 printf("cbrt(8.0) = %f\n", cbrt(x)); // selects the default cbrt
16 printf("cbrtf(3.375) = %f\n", cbrt(y)); // converts const float to float,
17 // then selects cbrtf
18}多线程
C11 新增了下面两个头文件用于对多线程的支持:
- threads.h,类似于 pthread 库
- stdatomic.h,提供原子变量以及与 C++ 类似的内存顺序
编码风格
错误处理
在传统 C 中,一般的做法是函数返回一个整型的错误码,错误信息通过读取一全局变量来获得。比如 libc,处理逻辑大致如下:
1void do_something(some_arg_t args, out_t *out) {
2 error_code err = do_task1();
3 if(err) {
4 goto error;
5 }
6
7 err = do_task2();
8 if(err) {
9 goto error;
10 }
11
12 err = do_task3();
13 if(err) {
14 goto error;
15 }
16
17 error:
18 ...
19}真正的返回值通过最后一个指针参数来传递。这种做法虽然历史悠久,但有如下两个弊端:
- 处理啰嗦。每个函数调用的地方需要处理错误,没法进行链式调用
- 强制进行一次内存分配。因为需要将返回值赋值给指针参数,因此不可避免的需要进行一次内存分配
Modern C and What We Can Learn From It 视频中介绍了另一种处理方式:直接返回一个 struct,里面同时包括真正的数据与错误信息:
1typedef struct {
2 char *data;
3 isize_t size;
4 valid_t valid;
5} file_contents_t;
6
7file_contents_t read_file_contents(const char* filename);其他函数在使用结果时,进行 contents.valid 判断即可,这种方式就解决了上面两个问题,使用效果如下:
1file_contents_t fc = read_file_contents("milo.cat");
2image_t img = load_image_from_file_contents(fc);
3texture_t texture = load_texture_from_image(img);
4
5if(texture.valid) {
6 ...
7}由于直接返回了值类型的 struct ,这间接减少了手动管理内存的压力。而且由于没有指针的指向,因此理论上程序会运行的更快。
API 封装
在上面介绍 C 的包管理时,介绍到了 C 程序使用类库时,只需要关心头文件,这里面定义了使用这个库的公开接口,也就是说实现和接口分开的。
不过一般意义上头文件只会对函数进行封装,只进行函数的声明,没有实现,但其实也可以对 struct 封装。比如:
1/* Opaque pointer representing an Emacs Lisp value.
2 BEWARE: Do not assume NULL is a valid value! */
3typedef struct emacs_value_tag *emacs_value;
4
5emacs_value init_value();这里的 emacs_value 就是对结构体 emacs_value_tag 的封装,结构体的真正定义在源码文件中,类库只需要提供该结构体的构造函数即可,用户不需要感知结构体大小与实现。
关于 C 的 API 设计,更多可以参考这个文档(PDF),这是它的讨论:
总结
作为一门历史悠久的语言,C 并没有过时,相反随着时代进步,它也在逐步演进。对于长期使用高级语言的程序员来说,刚转向 C 时,可能会觉得它功能太过简陋,开发效率低,但这其实只是表面现象,通过对整个生态圈的熟悉,这种感觉会逐渐消失。而且由于黑魔法少,程序员对整个代码库会更有控制感。
In the beginning you always want results.
In the end all you want is CONTROL.
在 V2EX 上讨论 💬
扩展阅读
- 漫谈 C 语言及如何学习 C 语言
- C 语言底层开发怎么样? - V2EX
- C 语言该怎么继续提高 - 闲聊灌水 - Emacs China
- Autotools Introduction (automake)
- Debugging and Profiling · the missing semester of your cs education
- One year of C
- Struct and union initialization - cppreference.com
- Modern C and What We Can Learn From It (YouTube)
- To Save C, We Must Save ABI | The Pasture
- C Isn't A Programming Language Anymore | Lobsters
- Learning C with gdb - Blog - Recurse Center
- Structures in C: From Basics to Memory Alignment