最近在写 Zig 时遇到一个奇怪的 bus error,下面是简化后的代码:
1fn foo(arr: *[3]u8) void {
2 arr[0] = 100;
3}
4
5pub fn main() !void {
6 const arr: [3]u8 = .{ 1, 2, 3 };
7 foo(@constCast(&arr));
8}直接 zig run main.zig 执行,会报错:
1Bus error at address 0x10464de2c究其原因,就在于 const 定义的数组是个常量,因此数据定义在 rodata 块内,因此 foo 函数运行时报错了,后文会分析如何确认这一点。
这个问题这也引起了我的一直以来的好奇心,即:一个程序在执行时,它内部的数据是怎么分布的?本文就带着上面问题,来尝试回答这个问题。
程序内存分布
在 TLPI 一书中,第六章的这个图很好的展示了一个程序的内存分布(Segments),地址从低向上增长,依次主要有:
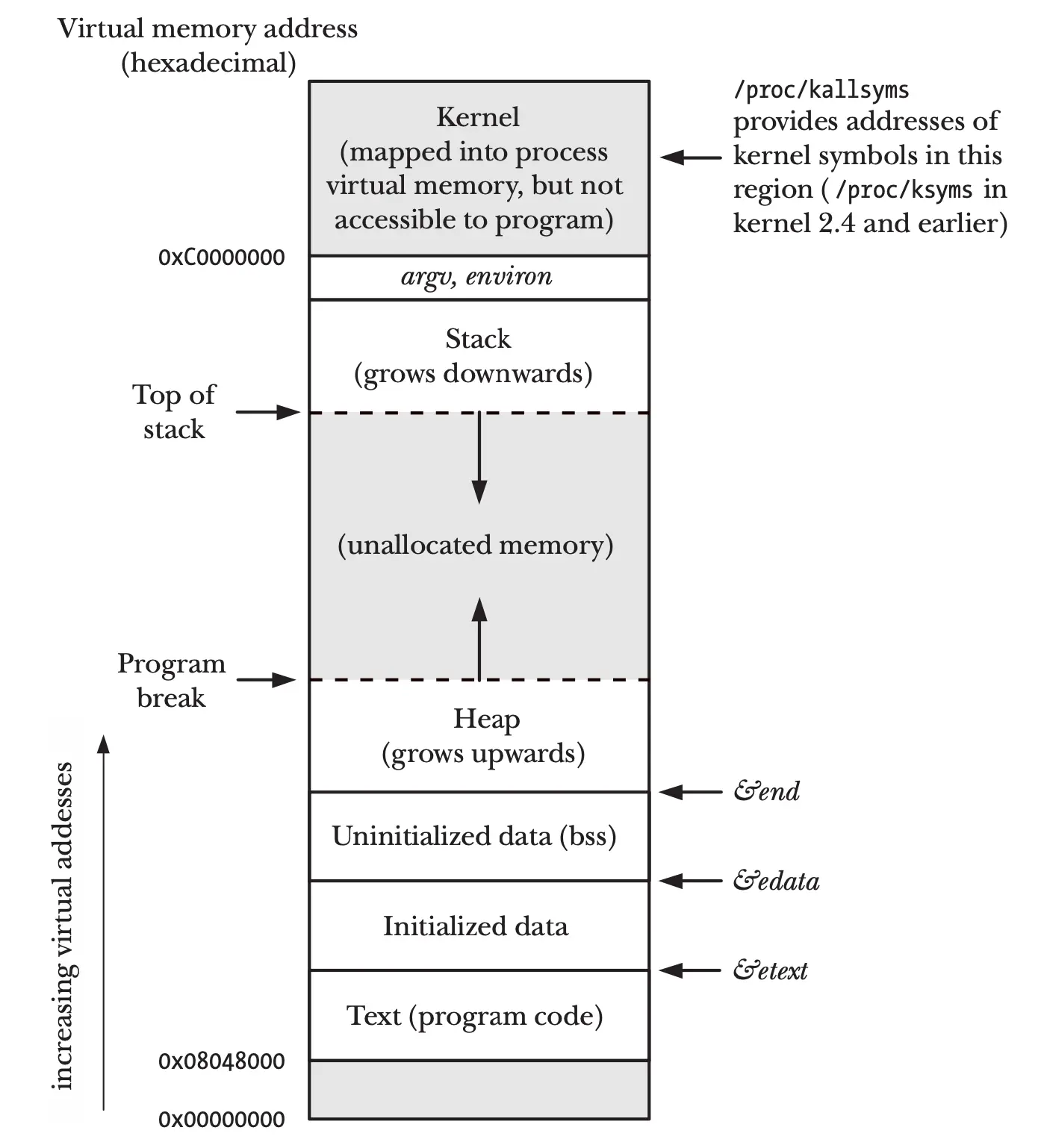
- Text,存放程序指令
- Initialized data,存放初始化的全局变量和静态变量的段
- Uninitialized data,存放未明确初始化的全局变量和静态变量。在启动程序之前,系统会将该段中的所有内存初始化为 0。 也称为:BSS,这个名称来源于一个古老的汇编程序助记符 "block startedby symbol"。将已初始化的全局变量和静态变量与 未初始化的全局变量和静态变量分开放置的主要原因是,当程序存储在磁盘上时,无需为未初始化的数据分配空间。 相反,可执行文件只需记录未初始化数据段的位置和所需大小,程序加载器将在运行时分配这些空间。
- Heap,存放程序在运行时动态申请的数据,Heap 的顶称为 program break
- Stack,在函数调用时动态扩缩容。每一次函数调用,都会新创建一个栈帧(stack frame),用了存放函数的参数、变量、返回值。很重要一点,栈是向下增长,地址逐渐变小。
在 Linux 上,我们可以使用 size 命令查看不同部分的大小:
1$ size a.out
2 text data bss dec hex filename
3 818744 136 24960 843840 ce040 a.outData 表示的是 Initialized data 区,dec、hex 是前三个区域的总和,dec 是十进制展示,hex 是十六进制。rodata 区域一般不展示,可以通过以下命令查看:
1objdump -s myprogram
2readelf -S myprogram
3
4readelf -x <section_index> myprogram也可以利用 GDB 的 info sections 和 x/<num>x <address> 命令来查看。
示例代码
下面是 TLPI 书中的一个例子,用于说明变量分配位置:
1#include <stdio.h>
2#include <stdlib.h>
3
4char globBuf[65536]; /* Uninitialized data segment */
5int primes[] = { 2, 3, 5, 7 }; /* Initialized data segment */
6
7static int
8square(int x) /* Allocated in frame for square() */
9{
10 int result; /* Allocated in frame for square() */
11
12 result = x * x;
13 return result; /* Return value passed via register */
14}
15
16static void
17doCalc(int val) /* Allocated in frame for doCalc() */
18{
19 printf("The square of %d is %d\n", val, square(val));
20
21 if (val < 1000) {
22 int t; /* Allocated in frame for doCalc() */
23
24 t = val * val * val;
25 printf("The cube of %d is %d\n", val, t);
26 }
27}
28
29int
30main(int argc, char *argv[]) /* Allocated in frame for main() */
31{
32 static int key = 9973; /* Initialized data segment */
33 static char mbuf[10240000]; /* Uninitialized data segment */
34 char *p; /* Allocated in frame for main() */
35
36 p = malloc(1024); /* Points to memory in heap segment */
37
38 doCalc(key);
39
40 exit(EXIT_SUCCESS);
41}栈帧
栈帧是函数调用时,保存函数内变量的内存区域,它在函数调用时自动创建,在函数返回时自动释放。由于这个特性,在 C 中,一般将函数内的参数、局部变量称为自动变量。
下图是 main -> doCalc -> square 这个调用链的栈帧示意图:

那我们如何确定一个变量分配的位置呢?不需要死记硬背,直接看看代码生成汇编就可以了。
寄存器
谈到汇编,就绕不开寄存器,下图是 x86 上的 8 个通用寄存器,可以以 16 位或 32 位方式访问。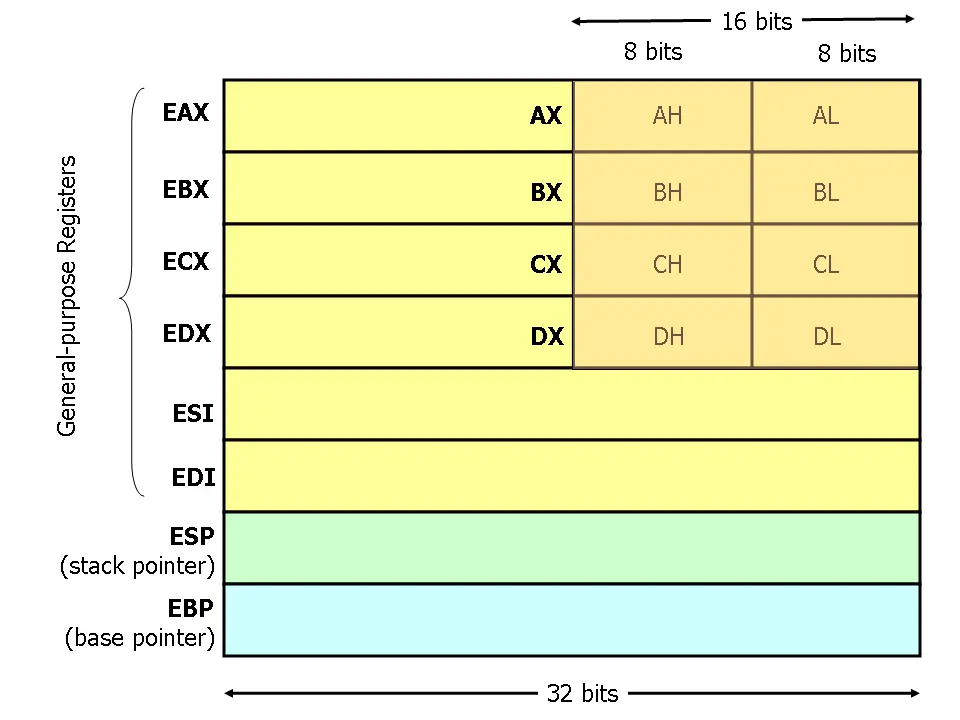
对于 64 位架构来说,前缀换成了 R,因此 64 位版本的 "EAX "被称为 "RAX",除此之外,64 位还额外增加了 8 个通用寄存器,r8 到 r15 。
其中,ESP 指向栈顶,EBP 指向当前栈基(即开始位置),这在后面讲述函数调用时还会用到。
指令
汇编指令大致分为三类:数据移动、算数运算、控制流指令,下面是一些常用的指令:
数据移动
mov把第二个参数赋值给第一个。mov的两个参数不能都是内存地址,必须用寄存器中转一下。1mov eax, ebx — copy the value in ebx into eax 2mov byte ptr [var], 5 — store the value 5 into the byte at location varpush向堆栈上写入一个元素。由于堆栈向下增长,因此这个命令就相当于 ESP 减 4,然后执行一次 mov 指令。1push eax — push eax on the stack 2push [var] — push the 4 bytes at address var onto the stackpop从堆栈上移除一个元素,写入第一个参数中。1pop edi — pop the top element of the stack into EDI. 2pop [ebx] — pop the top element of the stack into memory at the four bytes starting at location EBX.leaLoad effective address,将第二个操作数指定的地址放入第一个操作数指定的寄存器中。 注意,内存位置的内容不会被加载,只会计算有效地址并将其放入寄存器。 这对于获取内存区域的指针非常有用。1lea edi, [ebx+4*esi] — the quantity EBX+4*ESI is placed in EDI. 2lea eax, [var] — the value in var is placed in EAX.
控制流
x86 处理器有一个指令指针(EIP)寄存器,它是一个 32 位值,指示当前指令开始执行的内存位置。 通常,在执行一条指令后,该寄存器会递增,指向内存中的下一条指令。 EIP 寄存器不能直接操作,但可以通过控制流指令进行隐式更新。
jmp <label>跳转到指定 label 处。j<condition>这里其实包含多种指令。这些指令是有条件的跳转,其依据是存储在称为机器状态字的特殊寄存器中的一组条件代码的状态,机器状态字通过cmp指令修改。je <label>当相等时跳转jne <label>当不相等时跳转jz <label>当不是0时跳转jg <label>当大于时跳转jge <label>当大于或等于时跳转jl <label>当小于时跳转jle <label>当小于或等于时跳转1; eax <= ebx 时,调整到 done 处,否则继续执行下一条指令 2cmp eax, ebx 3jle done
callret子过程调用与返回指令。call会首先把下一条指令地址(即 EIP 寄存器)压入栈中,这样函数返回后就可以继续之前的逻辑执行。然后会 跳转到指定 label 处。相比jmp,它多了一个压栈操作。ret会从栈顶弹出返回地址,写入 EIP 中,使得程序继续从被调用函数的下一条指令开始执行。
调用约定
在进行子过程调用时,如何传递参数,如何获取返回值?这时调用约定(calling convention)就派上用场了。
C 语言的调用约定主要基于硬件支持的堆栈,它以 push、pop、call 和 ret 指令为基础,子程序参数在堆栈上传递,寄存器的值保存在栈上,子程序使用的局部变量放在栈上的内存中,大多数处理器都使用类似的调用约定。
调用约定主要涉及两方面:
调用者(caller),
- EAX、ECX、EDX 是 caller-saved 寄存器,为了防止子过程修改它们,调用者按需保存。
- 函数的参数倒序压栈,即第一个参数在低地址处
call指令会将当前 EIP 的值压栈,然后跳转到指定子过程中- 在从子过程返回后,从 EAX 获取返回值,并将函数的参数从堆栈中弹出,恢复 caller-saved 寄存器
被调用者(callee)
将 EBP 入栈,并把 ESP 的值赋值给 EBP,这样相当于保存了调用者的栈基,一般对应下面两条指令:
1push ebp 2mov ebp, esp- 接着,开始将局部变量入栈。由于 EBP 在整个子过程执行中不会改,因此就可以通过 EBP 加偏移量找到对应参数。
- 接着保存 callee-saved 寄存器,即 EBX、EDI、ESI
在子过程返回前,会进行
- 把返回值复制到 EAX 中
- 从栈中,恢复 callee-saved 的寄存器
- 释放局部变量。一种做法是 ESP 增加适当值,另一个更不容易出错的方式是直接把 EBP 赋值给 ESP。
- 在最后返回前,将调用者的 EBP 从栈中恢复,这与一开始的入栈操作相对应
- 最后执行
ret,此时栈顶的数据就是调用函数前下一条指令的地址,直接赋值给 EIP 即可
上面文字有些多,下面看一个具体示例,首先是调用者:
1push [var] ; Push last parameter first
2push 216 ; Push the second parameter
3push eax ; Push first parameter last
4
5call _myFunc ; Call the function (assume C naming)
6
7add esp, 12接着是被调用者:
1 ; Subroutine Prologue
2 push ebp ; Save the old base pointer value.
3 mov ebp, esp ; Set the new base pointer value.
4 sub esp, 4 ; Make room for one 4-byte local variable.
5 push edi ; Save the values of registers that the function
6 push esi ; will modify. This function uses EDI and ESI.
7 ; (no need to save EBX, EBP, or ESP)
8
9 ; Subroutine Body
10 mov eax, [ebp+8] ; Move value of parameter 1 into EAX
11 mov esi, [ebp+12] ; Move value of parameter 2 into ESI
12 mov edi, [ebp+16] ; Move value of parameter 3 into EDI
13
14 mov [ebp-4], edi ; Move EDI into the local variable
15 add [ebp-4], esi ; Add ESI into the local variable
16 add eax, [ebp-4] ; Add the contents of the local variable
17 ; into EAX (final result)
18
19 ; Subroutine Epilogue
20 pop esi ; Recover register values
21 pop edi
22 mov esp, ebp ; Deallocate local variables
23 pop ebp ; Restore the caller's base pointer value
24 ret
示例分析
回到本文一开始的代码,这是它在 Godbolt 上生成的汇编,核心代码如下:
1example.main:
2 push rbp
3 mov rbp, rsp
4 movabs rdi, offset __anon_1720
5 call example.foo
6 xor eax, eax
7 pop rbp
8 ret
9
10example.foo:
11 push rbp
12 mov rbp, rsp
13 sub rsp, 16
14 mov qword ptr [rbp - 16], rdi
15 mov qword ptr [rbp - 8], rdi
16 mov rax, qword ptr [rbp - 8]
17 mov byte ptr [rax], 100
18 add rsp, 16
19 pop rbp
20 ret
21
22__anon_1720:
23 .ascii "\001\002\003"可以看到,它的 call foo 时,根本就没有将参数入栈,因此这也说明 arr 的数据不是在 main 函数的栈帧中,有一点比较奇怪的是:对
rdi 进行了两次赋值。这是冗余操作,在 Release 模式下就没有这个问题。
修复方式也很简单,将 const arr 改成 var arr 即可,这时 main 的汇编如下:
1example.main:
2 push rbp
3 mov rbp, rsp
4 sub rsp, 16
5 mov ax, word ptr [.L__unnamed_3]
6 mov word ptr [rbp - 3], ax
7 mov al, byte ptr [.L__unnamed_3+2]
8 mov byte ptr [rbp - 1], al
9 lea rdi, [rbp - 3]
10 call example.foo
11 xor eax, eax
12 add rsp, 16
13 pop rbp
14 ret
15
16example.foo:
17 push rbp
18 mov rbp, rsp
19 sub rsp, 16
20 mov qword ptr [rbp - 16], rdi
21 mov qword ptr [rbp - 8], rdi
22 mov rax, qword ptr [rbp - 8]
23 mov byte ptr [rax], 100
24 add rsp, 16
25 pop rbp
26 ret
27
28.L__unnamed_3:
29 .ascii "\001\002\003"可以看到,在调用 call 前进行了 4 次 mov 操作,这就证明了这时 arr 是在栈上分配的。下面是在 ReleaseSafe 模式(同时关闭 inline)下生成的汇编代码:
1example.main:
2 push rbp
3 push r15
4 push r14
5 push r13
6 push r12
7 push rbx
8 sub rsp, 72
9 lea rdi, [rsp + 12]
10 mov byte ptr [rsp + 14], 3
11 mov word ptr [rsp + 12], 513
12 call example.foo
13 movzx r12d, byte ptr [rsp + 13]
14 movzx ebp, byte ptr [rsp + 14]
15 movzx r15d, byte ptr [rsp + 12]
16 movzx eax, r12b
17 movzx r14d, r15b
18 mov qword ptr [rsp + 48], rax
19 movzx eax, bpl
20 mov qword ptr [rsp + 40], rax
21 lock bts dword ptr [rip + Progress.stderr_mutex], 0
22 jb .LBB2_1
23
24example.foo:
25 mov byte ptr [rdi], 100
26 ret可以看到,四个 mov 指令变成了两个,而且 foo 函数内已经只剩两个指令,这是由于在 foo 内没有用到额外的寄存器,因此也就不需要进行压栈保存了。
1 lea rdi, [rsp + 12]
2 mov byte ptr [rsp + 14], 3
3 mov word ptr [rsp + 12], 513这里的赋值很有意思,513 的十六进制是 0x201,这一步就相当于同时对 arr[0] arr[1] 进行赋值, lea 指令相当于把数组的起始位置地址赋值给 rdi,因此在 foo 函数内直接执行一条 mov 指令就搞定了。
总结
为了弄清楚 bus error,本文梳理了程序的内存布局,堆栈在函数调用时的变化过程,这对于系统编程来说是十分重要的,而且了解必要的汇编知识,也有助于程序性能优化。
此外,在写本文过程中,重度依赖 Claude,有了大模型的加持,学习这些生疏的知识也轻而易举,直接把汇编代码输入,AI 即会给出详尽的解释, 不懂的地方还可以一直追问,可能读者也有类似感受,不知道今后的 AI 会发展成怎样呢?
参考
- Bus error vs Segmentation fault
- https://ziggit.dev/t/a-strange-bus-error-when-call-c-function-from-zig/5417
- Guide to x86 Assembly
- Where the top of the stack is on x86
- Stack frame layout on x86-64
- Lecture 6: Checking for errors and calling functions
- x86 Assembly/X86 Architecture
- Stack buffer overflow
- Stack Frames & Pointers | Cameron Wickes